
Abstract
We make the case for building a permanent public-use platform for conducting and analyzing immersive interviews on the everyday lives of Americans. The American Voices Project (AVP)—a widely watched experiment with this new platform—provides important early evidence on its promise. The articles in this issue reveal that, although public-use interview datasets obviously cannot meet all research needs, they do provide new opportunities to study small or hidden populations, new or emerging social problems, reactions to ongoing social crises, submerged values and attitudes, and many other aspects of American life. We conclude that a permanent AVP platform would help build an “open science” form of qualitative research that complements—rather than replaces—the existing very important body of immersive-interviewing research.
At the height of the 2008 financial crisis, Queen Elizabeth II asked, “Why did nobody see it coming?” When economist Paul Krugman delivered an address in Lisbon four years later, he owned up to the failure and placed the blame squarely on his discipline. Economists, he asserted, should be “ashamed of their profession” because it had failed to predict, much less coherently explain, one of the key crises of our time—the Great Recession (Krugman 2012). This was no small failure. The unemployment rate doubled between December 2007 and October 2009; one-fourth of American families lost at least 75 percent of their wealth over the first four years of the recession; and approximately ten million American households lost their homes over the recession’s full course (Pfeffer, Danziger, and Schoeni 2013). “Times of crisis are when economists are most needed,” Krugman continued. “If they have no useful advice to offer—the whole enterprise of economic scholarship has failed in its most essential duty.”1
Do sociology and other social sciences have a crisis-prediction record good enough to meet Krugman’s very reasonable standard? It would be hard to argue that they do. In many respects, the story of the twenty-first century is a story of cascading social crises, few of which have been successfully predicted, well monitored, or well understood. As Richard Bookstaber (2023) recently put it, we’re entering a new epoch of social crises, a “slow-motion tidal wave of risks” that may even pose an “existential threat to civilization.” In a recent Global Risks Report (World Economic Forum 2022), 20 percent of surveyed elites expected to see “tipping points,” “persistent crisis,” and “catastrophic outcomes” in the next decade, a steep increase relative to earlier assessments. Because these crises are often social—as much as economic—in structure, it is important to apply Krugman’s challenge more broadly to the social sciences as a whole.
When a broader census of social crises is taken, it quickly becomes clear that there is ample failure to go around, failure that has taken the form of ignoring or dismissing warning signs or underinvesting in relevant monitoring activities. The rise of political extremism—which has reinvigorated White supremacist ideologies, polarized civil society, challenged democratic forms of governance, and eroded trust in many institutions—was largely unpredicted and unanticipated and not well monitored until it was fully upon us. The social effects of the ongoing takeoff in natural disasters are also poorly understood. Across the nation, communities have seen a rapid acceleration of weather-related disasters (costing the economy $165 billion in 2022 alone), yet our capacity to monitor the social fallout from these crises is not well developed (National Centers for Environmental Information 2024). The COVID-19 pandemic, which has so far caused more than 1.3 million excess deaths in the United States (Centers for Disease Control and Prevention 2023b), revealed that critical real-time or near-time health and economic data were often unavailable, with the result that a host of new monitoring instruments had to be built on the fly (for example, Census Bureau’s Household Pulse survey, Kaiser Family Foundation COVID-19 Vaccine Monitor). The ongoing opioid epidemic has now claimed nearly a million lives, but social scientists only detected it well after the carnage began more than two decades ago (Centers for Disease Control and Prevention 2023a). The ongoing sharpening of geopolitical tensions and Cold War sensibilities has brought on a sharp rise in apocalyptic worldviews, an emerging crisis that has been largely ignored, barely monitored, and remains poorly understood (Davis 2022). A historic decline in fertility—which has left the United States with its lowest total fertility rate ever recorded—is yet another unanticipated and poorly understood crisis (Hamilton 2021). The “loneliness and mental health crisis,” which predated the pandemic but accelerated in tandem with it, was likewise in play long before it was diagnosed (Demarinis 2020; Twenge et al. 2021). And, finally, after decades of decline, we’ve seen a dramatic surge in homicide rates in 2020 and then a gradual decline thereafter (with 2023 rates still above pre-pandemic levels), a development that was not predicted and has triggered a sharp social and political fallout that continues to play out (Arango 2023).
Are we asking too much of social science? We don’t think so. Although even the most effective monitoring system may not have predicted the opioid epidemic, it should at least have been able to detect signs that a crisis of this kind was likely to emerge, especially in parts of the country (such as Appalachia) suffering from rising anomie and an epidemic of pain. As Paul Krugman said of the Great Recession, “Nobody could realistically have demanded that the economics profession predict that Lehman Brothers would go down on September 15, 2008, and take much of the world economy with it” (2012). But Krugman goes on to note that “What you can criticize economists for … is failing even to see that something like this crisis was a fairly likely event” (2012). Even by this relaxed standard, sociologists have likewise often fallen short. Although arguably there were many leading indicators of “something like” a rise in political extremism or “something like” a mental health crisis, the field has not been set up with the infrastructure needed to reliably detect these crises and many others.
The foregoing list of crises also makes it clear that the early prediction problem is hardly our only monitoring problem. We also need real-time monitoring of responses and adaptations to known crises and social developments. Even after a crisis is clearly in play, we still want a monitoring system that captures how the most affected people are coping and making sense of the crisis, how those who are more protected and privileged are interpreting it, and the causes lying behind the crisis. If, for example, our monitoring system failed to predict the rise of political extremism, we might still hope that it would at least provide evidence on how extremists make sense of the movement, how those opposed to extremism interpret it, and the social psychological or behavioral precipitants of an extremist worldview (such as perceived threats to social standing among rural Whites).2 This after-the-fact monitoring function is of course important not just for crises but also for social processes that develop more gradually into major social problems (such as rising income inequality).
No matter which monitoring task we are considering, either “early prediction” or “after-the-fact,” it is clear, then, that the social science record is hardly stellar. If Krugman was hard on economists, it is surely appropriate for other social scientists to likewise step up and accept some blame. We have evidently been so busy with our own narrow disciplinary concerns that we have forgotten that—at minimum—it is our job to anticipate, monitor, and interpret the many social crises of our time. Just as Krugman lamented that economics has let us down, so too the social sciences as a whole have often failed in one of their essential duties, that of alerting the nation to the most important crises and social developments. Although there is no guarantee that such alerts will be heeded, a core job of social science is to put the evidence on the table so the general public and policymakers can decide how best to react to it. The response to such warnings may well be one of disinterest or prolonged inaction. Even so, our job—as social scientists—is to expose the problems in a timely way, especially as we move into a new polycrisis period that places a premium on swift information-gathering.
The simple purpose of this introduction is to attempt to make some headway in envisioning how the country’s monitoring infrastructure could more successfully deliver on this need. We will start by asking why the existing infrastructure for monitoring has fallen short and then consider what is needed to improve it. To foreshadow our argument, we suggest that we need a permanent immersive-interviewing platform that elicits broad, open-ended conversations founded on openness, trust, and honesty. This new platform, which would supplement existing survey-based monitoring, would make it possible to directly listen to Americans at regular intervals, thereby accessing their interpretations, their sentiments, and their responses to ongoing crises.
The case for setting up such a platform does not rest exclusively on the need to detect new crises and monitor responses to known ones. Although we have stressed to this point the growing importance of crisis monitoring, it is no less important to carry out everyday monitoring of key attitudes and behaviors that evolve under the force of long-standing social and institutional processes (such as rationalization, marketization, individualization, othering) as much as sudden crises. We will show that a public immersive-interviewing platform can meet this need as well by allowing for ongoing real-time analysis of a shared, large-N, nationally representative dataset. It goes without saying that this new platform would never replace—but only complement—existing research traditions based on other very valuable research methods (administrative data, surveys, social media, qualitative journalism, and individualized immersive interviewing).
THE EXISTING MONITORING INFRASTRUCTURE
Before describing this new platform in more detail, it is useful to take stock of our extant monitoring system based on surveys and administrative data, social media content, qualitative journalism, and conventional forms of immersive interviewing. Although each of these approaches plays an important and irreplaceable role in our monitoring infrastructure, we will show that none of them ensures that the voices of all Americans are reliably monitored and analyzed in real time.
Real-Time Monitoring via Surveys and Administrative Data
If asked how the pulse of the American people is taken, most people would point to federally funded cross-sectional and panel surveys (such as the General Social Survey [GSS], the Current Population Survey, the Panel Study of Income Dynamics, and the National Health Interview Survey); surveys funded by philanthropic organizations and nonprofits (such as the Pew Research Center and Kaiser Family Foundation surveys); administrative data (such as tax records, educational records, and safety net program data); and key Census Bureau products (such as the decennial census, the American Community Surveys, County Business Patterns, and Small Area Income and Poverty Estimates). These types of surveys and administrative data products are indeed critical for monitoring purposes. We use them to monitor unemployment, poverty, income inequality, educational access, safety net use, incarceration, consumer behavior, health outcomes, social and political attitudes, and much more. Although work is ongoing to improve this infrastructure (via improved data linkage, new survey products, and more), no one would dispute that our constellation of survey and administrative products, when taken together, constitute one of the world’s premier quantitative monitoring systems.
But this infrastructure also has its limitations. The capacity to detect what is happening on the ground via surveys and administrative data rests on the assumption that survey designers know which questions to ask; that the items on administrative instruments, which have been designed to meet narrow organizational agendas, can be successfully repurposed for other agendas; that survey takers will consent to participate and that selectivity in providing consent is minimal; that respondents can or will provide accurate responses; that closed-ended responses suffice to capture all that needs to be known; that we have the requisite budget and organizational capacity to add new items frequently, to collect data frequently, and to release it to analysts in real time; and that funders can be convinced that the proposed survey is sufficiently valuable. Because some of these assumptions will not be met (and perhaps never can be), it is hardly surprising that social scientists have often failed to detect crises in a timely way or to lend critical insights into them quickly enough to inform the immediate policy response. The existing infrastructure places impossible demands on survey designers, survey respondents, and repurposed administrative instruments and thus leaves a boatload of dark matter that is simply not amenable to the forced-choice survey, at least not in its current incarnation.
It is possible, to be sure, that we will eventually get better at identifying and incorporating key survey variables and ultimately explain the social world more satisfactorily within the confines of the survey tradition. But that is an exceedingly long-term proposition that will not help us get the job done now. In our crisis-laden century, there is arguably an imperative to improve our monitoring infrastructure in the short term, and it seems unlikely that doubling down on the survey form alone will suffice.
Real-Time Monitoring via Social Media Platforms
This is all to suggest that, insofar as our monitoring relies on the closed-ended survey, we are making a big bet that social scientists are prescient enough to know what types of dark matter should be exposed and thus what questions to ask, seemingly a big ask in a polycrisis environment that could engender relatively rapid changes in sentiments and behaviors. This leads us to ask whether the still-burgeoning stream of social media monitoring can solve this problem. It might be thought, after all, that the open-endedness of platform-based expression (Instagram, Facebook, TikTok, Reddit, X) nicely eliminates the need for the prescient social scientist and thus makes for an increasingly useful monitoring instrument in the twenty-first century.
Given how much time is now spent on social media platforms (Perrin and Atske 2021), no one can dispute the importance of understanding what is happening on them. Although platform-monitoring research is thus immensely useful, it is nonetheless difficult to harness for monitoring trends in everyday attitudes and behaviors. This is because such research can only provide evidence on the highly culled sample that contributes to a particular platform (the selection problem), cannot always distinguish human from nonhuman participation (bots, AI-generated content), can only reveal how the participating subpopulation reacts to the primes embedded in the structure of the platform and the user’s idiosyncratic feed (the priming problem), cannot be assumed to reveal the equally important constellation of attitudes and behaviors that are evoked off platforms (the generalization problem), and raises ethical concerns that have not yet been fully resolved for panopticon-style monitoring and many other forms. The selection problem is in fact deeper than it appears because many platform users are mere lurkers who never contribute data and thus engender yet another form of missing data (McClain et al. 2021). The priming problem is also deeply problematic for monitoring because users are exposed to a rapidly changing environment of feeds (with the nature of these changes also differing across users). Although it is possible that one could statistically control for such priming effects, the task is dicey given the very complicated changes in platform environments across users and over time. The generalizability problem refers to an even more fundamental priming effect that is likely insurmountable without substantial side evidence on offline life (Gonzalez-Bailon 2023). The obvious problem here is that we simply cannot know whether online discussions are sufficient without also knowing what is happening offline. These various challenges, taken together, make it difficult to rely exclusively on social media analyses for gauging trends in racial or gender animus, bullying and assault, toxic political beliefs, social isolation and estrangement, meaninglessness and anomie, social deprivation, and all manner of other key attitudes or behaviors.
This is not to deny in any way the importance of monitoring platform behavior. Because many people spend substantial time on social media platforms, we surely need to know what is happening on them. But we also need tools that solve the selectivity problem by listening to the voices of those who are and are not active on platforms, that solve the priming problem by delivering a controlled prime that is tuned for the research purpose at hand, and that solve the generalizability problem by examining offline as well as online behavior. We will show that a public immersive-interviewing platform can make some headway on each of these problems.
Real-Time Monitoring via Qualitative Journalism
The third prong of our monitoring infrastructure—qualitative journalism—has increasingly taken on monitoring functions that surveys or social media can’t easily handle. Because social media analyses mainly speak to online behavior, and because survey and administrative data often lack depth and cannot easily be analyzed in real time, qualitative journalism has come to play a critical—if largely unacknowledged—role in our current monitoring infrastructure.
This turn to qualitative journalism was nicely illustrated during the early months of the pandemic. Were people lonely during the early shelter-in-place orders? We turned to journalism to find out (Halpert 2020). What was behind the so-called Great Resignation? We turned to journalism to understand it (Gelles 2022). How were Americans talking about race and racism as the Black Lives Matter (BLM) protests took hold? We read the immersive interviews that journalists provided to learn more (Issawi 2020). How did essential workers handle the risks that were suddenly thrust upon them? Journalists again gave us the early answers (Ward 2020; Sharp 2020; Greenhouse 2020). In all these cases, social scientists eventually waded in and provided important scholarship, but only after millions of readers—including employers, public intellectuals, politicians, and other leaders—had their views shaped by the early qualitative evidence that only journalism was providing. It is in this critical sense that we already have a real-time monitoring infrastructure that shapes our early policy response. The obvious danger here is that we often act on this information without knowing how accurate it is.
Although the United States has increasingly turned to qualitative journalism for real-time monitoring, it has done so partly because it has nowhere else to turn. It would be hard to argue, after all, that the evidentiary foundation of qualitative journalism (sometimes comprising as few as two to three interviews) is sufficient to the task, a conclusion that should not surprise given that journalism was never set up to meet the evidentiary standards of science. It does not have the infrastructure or funding models that support large-N analysis, probability sampling, and that all-critical capacity to sort out competing accounts via sustained secondary analysis. It also does not have the normative guardrails that are fine tuned for scientific objectives. The concept of reproducibility within journalism is, for example, wholly incommensurable with the scientific understanding of that concept. When journalists refer to reproducibility, they are invoking the assurance that, if the specific informants featured in the article were reinterviewed, they would confirm that they were correctly quoted and that the quoted material was consistent with their experiences. This formulation does not deliver the assurances that are needed for high-quality monitoring. If we are to monitor well, the key question is not whether the interviewees were correctly quoted (although obviously that is a necessary condition for good science), but whether they are representative of the group being described and can therefore be used to characterize that group. This scientific concept of reproducibility is hardly an esoteric one. Even everyday readers of qualitative journalism are typically interested in the central tendency and almost certainly treat the provided quotes as representing just that (unless the quoted people are famous and of intrinsic interest in themselves).
This is all to stress that, because journalism is set up to deliver on the journalistic mission and responds to incentives that are not fine-tuned to the needs of science, it cannot necessarily be counted on to deliver fully on the real-time monitoring function. The core job of journalism is to report on current events, to deliver opinions and interpretations, and to hold power accountable. It is wrong to criticize it for failing to carry out science-based monitoring when doing so is hardly its job and when another institution—social science—has that job as its explicit charge.
Real-Time Monitoring via Scholar-Driven Immersive Interviewing
The immersive interviewing carried out within academic social science is a critical fourth prong of our monitoring infrastructure. This academic tradition of immersive interviewing has been built out quite systematically and, as a result, overcomes many of the problems that emerge within its journalistic version. As a social science method, the immersive interview offers the opportunity to capture rich information on how people think, feel, and act (as described in their words), all of which are key assets in detecting new crises and monitoring responses to existing ones. Because it is such a powerful method, it is taking off in all social science fields, even the social-science-adjacent fields of psychology and management (see figure 1).3 As sociologists Mario Small and Jessica Calarco (2022) recently concluded, the “importance of interview… methods to social science, and to society, is not in question.”

Proportion of Articles Using Qualitative Interviews
Source: Authors’ tabulation based on Thelwall and Nevill 2021.
Although few, we suspect, would challenge this conclusion, this does not imply that immersive-interviewing research has fully delivered on all the many objectives to which it can be put. It has fallen short, in particular, for purposes of real-time monitoring because it is not typically built on a repeated cross-section design that makes it possible to benchmark change against a known baseline, not always based on samples that are large enough to reach reliable conclusions about the population of interest, and not typically based on samples that are representative of the population of interest. We appreciate that these methodological strictures are not relevant for all the various types of immersive-interviewing research in play. Moreover, even when the researcher’s objective is to monitor trends, it is entirely possible that small nonprobability samples will pick up the trend of interest. It is hard not to be impressed by many notable successes of this sort (Edin and Shaefer 2015; Desmond 2017). The core problem, however, is that in the heat of the moment (such as a cascading crisis) we will just never know whether a small nonprobability sample is in fact delivering. If much is at stake in getting it right, we are therefore well advised to carry out complementary studies that rest on a comparable benchmark from the past, a sample size large enough to make it unlikely that sampling variability is driving the apparent trend, and a sampling design that ensures that an artifactual trend has not been generated by changes in the processes by which respondents are selected into the sample.
It is costly to meet these standards. To date, neither the government nor the country’s main philanthropic foundations have been prepared to fund immersive-interviewing research at anything approaching the amounts that currently go to fielding quantitative surveys, building quantitative administrative datasets, or supporting big quantitative research teams. Because immersive interviewing does not typically have access to this level of funding, it continues to take a do-it-yourself individualized form that produces myriad small-scale, unrepresentative, single-use data sets that are privately owned. Under this individualized form, each researcher collects their own dataset tailored to the research question they are taking on, a style of research that has been immensely productive but makes benchmarking, trend analysis, and comparison harder to undertake.
The long-standing presumption has been that immersive interviewing is intrinsically a small-scale individualized operation and that it has remained as such not because it has been starved of funding but because it is well suited for that mode of production. This presumption has never been put to the test because the research field has not been given access to the funding needed to allow for experimentation with other modes of production. The swift ramp-up in public funding for the social sciences privileged quantitative work because, unlike qualitative work, it had the “look and feel” of the natural sciences (Solovey 2020). Fueled by the resulting expansion in funding, quantitative scholarship shifted out of the small-scale individualized mode of production (in which individual scholars were responsible for collecting their own private-use datasets), and the multidomain (omnibus) public-use survey became a go-to source for quantitative scholars in many fields. These new datasets were much larger than their predecessors, relied heavily on new methods of probability sampling, and made it possible for researchers to hand over the task of data gathering to specialist data collectors in government or other professionalized research firms. The key point here is that the very same transition out of this individualized small-scale mode of production could not possibly have happened within the qualitative field because the requisite funding was not made available to a field that was derogated as unsystematic and unscientific.
Because qualitative research remains underresourced to this day (and especially so relative to its impact), most qualitative scholars accordingly have little choice but to resort to small nonprobability samples, even when they are attempting to monitor trends in ways that might require larger representative samples.4 As a result, we simply do not know whether the field would benefit, as has the quantitative field, from developing big public-use datasets that stand alongside the existing individualized research mode. The purpose of the American Voices Project, to which we now turn, was to undertake just that experiment.
THE EXPERIMENTAL AVP
To this point, we have argued that the country’s current infrastructure is not always getting the monitoring job done, given the threefold problem that survey and administrative data do not capture the dark matter of our lives, that the variegated primes delivered within social platforms likewise are not fine-tuned to uncover this dark matter, and that existing immersive interviewing within journalism or academia—both of which have the capacity in principle to unlock that dark matter—have been harnessed to modes of production (journalism, small-scale academic projects) that are not funded or organized in ways that always allow them to deliver fully on that capacity. To take on these problems, David Grusky and Kathryn Edin (along with several thought partners) came together some ten years ago to begin planning what would become the American Voices Project. Although they envisioned a public dataset modeled after the GSS, the AVP would allow researchers to hear directly from the American people in their own words, thus unlocking the dark matter.
To reduce costs, their plan was initially very modest. It entailed using survey and administrative data to identify the key types of communities across the country and to then choose one community of each type for immersive interviewing. In 2015, at a meeting at the Russell Sage Foundation with leading academics and potential funders, economist Greg Duncan challenged the AVP team to think bigger. What was needed, he said, was a large, representative study where all Americans—not just those within the exemplar communities—had an equal chance of being heard. Following the model of the GSS, we then embraced the vision of creating a permanent platform that was based on a probability sample, that oversampled low-income Americans (because they lack the money, power, and networks to be adequately heard), and that would be open to secondary analysis.
In 2016, a distinguished group of quantitative and qualitative scholars came together to fulfill this vision, with plans to launch an experimental immersive-interviewing platform (the experimental AVP) funded by many of the country’s top foundations and supported (via key staff infrastructure) by a coalition of Federal Reserve Banks (Alexander et al. 2017). After two years of piloting in seven communities across the nation, the AVP was fielded from 2019 to 2022 as the country’s first qualitative data-collection effort that was nationally representative, large-scale (2,700 interviews), and multiple-domain (omnibus). Based on its signature tell-me-the-story-of-your-life prompts (with semi-structured probes), the AVP would, it was hoped, engender the deep listening that could provide evidence on the everyday experiences, thoughts, feelings, and behaviors of a representative sample of Americans. The main objectives were to collect new types of data on the social scientific issues of the day, to explore the feasibility of establishing a permanent AVP platform, and to examine whether this platform might address some of the problems with using current immersive-interviewing research for purposes of real-time monitoring.
Just as the GSS, for example, seeks to cover a host of life domains, so too the AVP was conceived from the start as an omnibus study. After delivering the tell-me-the-story-of-your-life prompt, the AVP probed on a broad range of life domains via open-ended, nonjudgmental questions. It addressed such topics as the rhythm and routine of everyday life in the family, neighborhood, and workplace; employment, earnings, and job search; household spending and consumption practices; health and health care of family members; experiences with schooling and childcare; mental health, drug use, anxiety, and stress; parenting, family conflict and trauma, and family support; views on religion and meaning in life; political views and voting behavior; and attitudes about race, racism, social class, and inequality. The prompts also yielded detailed information about expenditures and income, including resources gleaned from cash and in-kind social programs (which notoriously suffer from underreporting problems in surveys), informal sources of income, and other ways of making ends meet.5 Although the core tell-me-the-story protocol was abstract enough to capture a host of possible and often difficult-to-anticipate reactions to systemic challenges, the AVP additionally included several special modules that made it possible to garner unstructured reactions to prominent current events (for example, prompts about the COVID-19 pandemic, the Black Lives Matter movement, the storming of the Capitol, anti-vaccination attitudes).
These tell-me-the-story prompts, which were delivered holistically as part of an engaging conversation lasting approximately ninety minutes, were followed up with a request to link to past, present, and future administrative data. In the experimental AVP, 82 percent of all respondents consented to such linkages, a rate consistent with that secured in other studies. The resulting linkages, in conjunction with short follow-up surveys (delivered via text message), make it possible to convert each round of the AVP into a panel at relatively low cost. The AVP study then concluded with a short survey ascertaining demographic data and other well-validated survey staples (such as health, mental health, stress and anxiety, political views, perceived social standing, trust, experiences with discrimination).
When the AVP initially went to field in the summer of 2019, all interviews were conducted in person, with teams of interviewers moving across sites. After the COVID-19 pandemic broke out, the protocol was retooled for remote interviewing, and remote fieldwork resumed after a short hiatus. This pandemic-induced retooling obliged the AVP team to develop innovative techniques for remote interviewing that maintained the quality of face-to-face interviewing. These new techniques, which also brought substantial cost savings, are now being further developed as we plan for a permanent AVP platform.
THE ANTICIPATED PAYOFF
We turn now to discussing some of the research benefits coming out of the experimental AVP. It is important to do so because a permanent immersive-interviewing platform is costly and should of course only be built insofar as the research payoff is accordingly substantial. We begin by laying out some of the research benefits that had been anticipated by the AVP team and then examine whether these benefits have been realized by the contributors to this issue as well as other early AVP researchers.
Improved Monitoring
At the start of this essay, we stressed the need to build a better monitoring infrastructure, a twofold task that entails increasing the country’s capacity to detect early signs of emerging crises (the discovery objective), and increasing the country’s capacity to monitor how people are reacting to and coping with known crises and other rapidly developing social processes (the coping objective). Because we have already discussed these two related objectives in some detail, all that needs to be noted at this point is that the AVP protocol was explicitly designed to deliver on each of them. The tell-me-the-story prompts open windows of discussion across a host of life domains (such as work, religion, family formation, politics, health) that provide rich opportunities for discovery. At the same time, these prompts provide opportunities to understand how respondents are coping with known crises, given that they directly reference life domains and activities that would presumably be affected by most any crisis (loss of work, health challenges, loss of income). To provide further evidence on coping behaviors, the AVP protocol was periodically revised to include new prompts that directly referenced important new developments while it was being fielded. Because the AVP was fielded at a time when many crises played out, there is ample opportunity to assess its value in understanding how people cope with them.
Supporting Cumulative Science
We have emphasized the value of the AVP for real-time monitoring because its large-N, representative, public-use design is especially advantageous for monitoring. But many other types of immersive-interviewing research could benefit from a public-use dataset. The AVP should be helpful, for example, in developing a cumulative form of qualitative research oriented to assessing and extending existing findings coming out of immersive-interviewing and other methodological traditions. This work is important to undertake because some of the most influential research in the immersive-interviewing field has been based on small or unrepresentative samples and could benefit from the follow-up analysis that the AVP makes possible.
The value of public-use datasets—within qualitative and quantitative fields alike—is that they provide researchers with a common test bed and data resource that allows for cumulation within a defined data zone. Because this zone covers core institutions (work, family, politics, religion, neighborhoods, health), a strong case can be made for focusing a stream of research on them. Although there is inevitably contestation about what constitutes the core, the virtue of undertaking this process is that it carves out a zone in which cumulation can happen. It generates a concentration of scholarship on core topics, the opportunity to carry out secondary analyses, and ultimately the capacity to yield consensus findings that then become the basis of cumulative science and policy. The foregoing is of course a long-run process, but our hope is that the initial round of experimental AVP analyses (which are partially represented in this issue) will open lines of inquiry that at least hold promise of generating cumulation of this sort.
The simple goal, then, was to expand the footprint of immersive-interviewing research by complementing the existing very successful form with a new defined data zone in which cumulative research is supported. This new form is in no way a substitute for the existing form; that is, just as the GSS’s defined data zone can never replace all the critical quantitative work occurring outside it, so too the AVP’s defined data zone is but a small complement to the vast amount of critical immersive-interviewing research occurring outside it.
Enabling Discovery
It was hoped that this cumulation would occur in conjunction with a parallel stream of discovery research oriented to generating new hypotheses. The latter line of work entails mining the AVP data for discoveries, not just discoveries that take the form of early warning signs of emerging crises (as we have stressed to this point), but also all manner of other discoveries within the various life domains that the AVP protocol covers. The simple point here is that such discovery work will likely be more successful when samples are large, when they are representative of the groups of interest, and when the underlying data are available for secondary analysis and can therefore be contested and extended.6
The extent to which AVP data can indeed generate high-quality discoveries of this sort is open to question. When a division of labor is installed between data collectors and data analyzers (as is the case with all public-use datasets), it means that the analysts are no longer directly participating in the interviews and therefore cannot engage in follow-up exchanges that allow them to pursue promising leads or to address pressing unresolved questions. The AVP trial analyses provide invaluable information on the types of research for which such follow-up exchanges are or are not critical. If we find that public-use datasets can generate high-quality scholarship for a wide range of research questions, it will reduce entry costs into the field and open up new opportunities for students, journalists, and scholars who cannot secure the release time or research support to build their own datasets.
The Payoff to Omnibus Datasets
The defining feature of conventional immersive-interviewing research is a circumscribed division of labor in which a single scholar (sometimes running a small team of research assistants) is responsible for study design, data collection, and data analysis. Under this mode of production, data are typically collected for a single targeted study topic, as no institutionalized mechanism for data sharing or pooled data collection is available (in ways that would yield, for example, an omnibus dataset). The field thus ends up with a host of narrowly siloed and incommensurable datasets that are each tailored to a single research question. Because this approach has, as we have already stressed, yielded a long stream of highly successful studies, no one should question its value or the importance of continuing to build and support it in its current form. The premise of the AVP is simply that this very successful research stream should be complemented with a parallel form of analysis that exploits the multiple-domain data coming out of an omnibus instrument. It is hard to justify the convention that public and philanthropic funding should only be provided for quantitative omnibus datasets.
Why are omnibus datasets, such as the AVP, likely to be valuable within the immersive-interviewing field? It’s not just that pooling data-collection efforts via omnibus studies is more efficient and reduces overall demand on respondents. Even more important, the key research case for an omnibus dataset is that, because information on many life domains (family, education, work, religion, politics) is simultaneously available, new opportunities are opened to make unforeseen cross-domain connections and discoveries. This omnibus opportunity is precisely why the NSF-funded General Social Survey (and similarly comprehensive quantitative datasets funded by other government agencies) have been so successful and have spawned so much breakthrough research. By collecting hundreds of quantitative variables spanning many domains, these datasets have enabled discoveries that were never intended, envisioned, or mandated by the data collectors themselves. The AVP adopts the same omnibus logic as the GSS but applies it by collecting cross-domain narratives rather than cross-domain variables.
The presumption, then, is that just as GSS researchers bring together variables from multiple domains in unanticipated ways, so too AVP scholars will be able to make productive cross-domain connections that lead to important discoveries. Do early traumas leave an imprint across many life domains? Are political extremists (populists) distinctive in an across-the-board fashion that shows up in their family life, religious life, work life, and neighborhood life? Are the lifestyles of social class members likewise distinctive in this across-the-board sense? Or are they instead very heterogeneous because of intersections with other identities? Are workplace decisions deeply affected by events in other life domains (family, religion, politics)? The AVP should make it possible to approach these types of bread-and-butter questions in new and productive ways. Because the AVP corpus of text is relatively large, it will often be useful to approach these questions with machine learning and natural language processing.
Understanding Hidden Populations
The voices of people who are derogated or stigmatized, excluded from mainstream society, or othered in some way are largely unheard and almost always unheeded. The qualitative research tradition has long been committed to studying just such hidden populations and thereby giving voice to those who are voiceless. This work is invaluable. Because it is very costly to study hidden populations, it has not always been possible, however, for qualitative researchers to deliver fully on their commitment to learn from those who have been marginalized. As sociologist Stefanie DeLuca (2022) notes, this representativeness problem has taken two forms: the voices of subpopulations that are expensive to sample are less frequently heard, and the voices of subpopulations that tend to fall into convenience samples are too frequently heard. The former problem means, for example, that there are many more studies of people in the urban North than in the Deep South (given that the urban North has more universities and is therefore easier and cheaper to access), whereas the latter means that even within the urban North there are too many interviews of people who are living very close to universities and thereby prone to falling into the convenience samples of the university’s qualitative researchers.
The AVP, because it implicitly shares costs across many users, can bear the high cost of interviewing difficult-to-reach populations and thus help overcome these problems.7 In the typical small-scale research form, each study typically operates under a stringent budget, given that the interviews will only be used once. With a public-use dataset, the large number of users renders a more expansive budget justifiable (from the point of view of government or philanthropic funders), thus making it possible to increase the sample size, pay the premium for probability sampling, and thereby access small and difficult-to-reach populations. This capacity to listen to rarely heard voices may well be one of the most important payoffs to the AVP.
THE ACTUAL PAYOFF
Given this setup and overview, we can now review the analyses that have thus far come out of the AVP. The AVP data have been analyzed in an initial round of crisis monitoring reports covering the pandemic as it unfolded, a second tranche of analyses that are appearing now in this issue, and a third overflow tranche that was opened to meet the substantial demand that could not be met via our partnership with the Russell Sage Foundation. These three experimental rounds of analysis were undertaken in hopes that they will help the AVP team finalize the dissemination process for the full public release of the experimental AVP. Because this preparatory work was pressing, the AVP team proceeded with these experimental releases before all interviews were completed and transcribed, before all variables were cleaned and available, and before the administrative data linkages and follow-up surveys were available. This means that the analytic samples were often small and that the data needed for many important types of analysis were not yet available. The analyses discussed here should therefore be understood as a small and incomplete subset of those that will ultimately be possible.
The researchers featured in this issue were the very first to test the secure server environment that the AVP team is building for future high-volume public use. To protect the confidentiality of AVP interviewees, all analyses had to be completed within this secure environment, and interviews were only made available after redacting identifying data (such as names, addresses, and employers). The articles themselves were released only after they passed disclosure avoidance review (that resulted in further redactions, suppression of small cell sizes, and other confidentiality-protecting interventions). These protections did of course slow down the analyses and subsequent review process. We are working to streamline our processes by drawing on ongoing efforts by the Census Bureau and leading survey firms to improve protocols for deidentification, noise-infusion, and disclosure avoidance review (Pascale et al. 2020).8
Monitoring in a Crisis Economy
It is fitting to start with the AVP’s monitoring analyses given that, from the outset, the AVP has been conceived as a resource for real-time monitoring. As an initial test of its monitoring capacity, we completed an experimental series of crisis monitoring reports based on analyses of the AVP interviews in the midst of the pandemic, an initiative that was funded in part by the Bill & Melinda Gates Foundation. During this critical period in history, the AVP’s intrepid team of interviewers was invaluable, often serving as interviewers by day and report-writers by night. The key research objective for these reports was to provide an ongoing, direct, real-time window into the voices of the people as one crisis after another coursed through the country. The resulting reports were among the first to identify how people reacted to being isolated and alone at home, to the loss of jobs and the ramp-up of pandemic relief, to the stark increase in health inequalities, to the new class divide between face-to-face and remote work, to the burgeoning Black Lives Matter movement, to the storming of the Capitol, and to the vaccine rollout (Mattingly et al. 2021; Coleman et al. 2022; Freese, Johnson, and Garcia 2021; Grusky et al. 2021; Jackson et al. 2021; Fields et al. 2022).
Although we will not review these reports in any detail, it bears stressing that sometimes their portrait of everyday life resonated with the conventional journalism of the period and sometimes it did not. We should not treat reports that are wholly consistent with journalistic accounts as any less valuable. Because the immersive interviewing within journalism often informs the country’s early policy response (despite being based on small or unrepresentative samples), it is important to undertake this testing even when it simply shows that journalism got it right. It is also important, whenever it proves necessary, to use the AVP to revise and extend the accounts coming out of conventional journalism. The reports served this function as well. As but one illustration, it is useful to consider the extensive journalistic treatment of the BLM movement, a treatment that often featured widespread optimism about opportunities for “significant, sustained, and widespread change” (Buchanon, Bui, and Patel 2020). In a crisis report authored by Corey Fields, Rahsaan Mahadeo, Lisa Hummel, and Sara Moore, a core finding was that discussions of systemic change were not as prominent as we might think, indeed even the most liberal White respondents were not typically focused on it. To the contrary, they tended to focus on issues of personal growth and awareness, with the objective of understanding and coming to terms with their own privilege. For liberal White respondents, the BLM movement was principally an opportunity to recognize and talk about their privilege, but not so much an opportunity to consider in any fulsome way the institutional changes that might reduce that privilege. By contrast, Black respondents viewed the protests of 2020 as a mandate to move beyond such therapeutic projects to concrete reform, institutional change, and restitution. The report concludes, “Although the ways in which Black and white people talk about race has long differed, the protests of 2020 may accordingly be seen as a wedge event that sharpened this conversational divide” (Fields et al. 2022). Elsewhere, we return to the implications of this divide, but for now we simply want to stress that our real-time analyses helped us better understand what is happening on the ground as different groups came to terms with social change in different ways.
The second tranche of experimental AVP articles (those appearing in this issue) allow us to examine the payoff to crisis monitoring when it takes a slow science—rather than real-time—form. Although the Russell Sage Foundation call welcomed research on all topics, a great many applicants proposed to consider whether conventional survey research, social media monitoring, or journalistic reporting on pandemic society had missed important developments. We did not select too many proposals of this sort because the crisis-monitoring reports already filled this niche and because the window for real-time monitoring had largely passed (given that the AVP data-collection period had ended). We did, however, select some crisis-monitoring proposals to garner additional evidence on the payoff to building a permanent immersive-interviewing platform.
Did these articles bear fruit? In addressing this question, it is useful to begin with the article by Kyle Fee, Sloane Kaiser, and Keith Wardrip (2024, this volume, issue 4; “Catching Up and Coping in the COVID Economy”), a nicely ambitious effort to understand the economy in the midst of the pandemic. The setup for this article is the many competing narratives about how low-income households were faring in the pandemic. Whereas some commentators have argued that pandemic relief programs restored low-income households to a “firm financial footing,” others have highlighted the “financial distress that persisted in spite of these programs.” As the authors point out, it has been difficult to adjudicate between these competing accounts using administrative data, given that what is truly dispositive is not so much the objective circumstances of households as their reactions to and interpretations of those circumstances. The AVP data are accordingly well suited to add to the discussion. Although the authors note that much of what they found aligns with research based on surveys or administrative data, they also emphasized that this research has not sufficiently appreciated the “acute financial difficulties” that the pandemic engendered. To make ends meet, low-income households struggled in a host of ways (such as taking on debt, borrowing from family or friends), but most prominently by turning to the gig economy and older informal-economy forms (babysitting, fixing appliances, selling handmade goods). These struggles to make ends meet led to “heightened levels of stress, worry, and anxiety” that “challenge the broader notion of households on firm financial footing as a result of the pandemic relief programs.” The authors conclude that a permanent immersive-interviewing platform would be a “powerful complement to the growing suite of real-time quantitative data” on the economy.
The other two articles in this section provide a complementary portrait of a pandemic economy that has generated more distress than has typically been appreciated. In the article “Some Surviving, Others Thriving,” by Catherine Thomas, Michael Schwalbe, Macario Garcia, Geoffrey Cohen, and Hazel Rose Markus (2024; this volume, issue 4), we learn that a large swath of structurally disadvantaged Americans was mostly “just surviving,” given that they were dealing with “major life chaos” because of health and financial problems. Although they tried to cope with this chaos via “persistent high effort and emotional restraint,” the authors worry that the American cultural imperative to avoid the negative and seek the positive conceals the extent to which people were being pushed to the breaking point. Because the AVP’s interviewers were trained to cultivate open and trusting conversations, they were sometimes able to break through this silver lining imperative, often finding that underneath it lies more discontent and distress than has been appreciated. This distress frequently arises because many people feel that their financial and life challenges are not respected, appreciated, or even seen by others and that they are therefore struggling all alone. The third article in this section—authored by Theresa Rocha Beardall, Collin Mueller, and Tony Cheng (2024; this volume, issue 4)—shows that crisis-induced inequalities are further magnified because many groups face profound administrative burdens when engaging with the high bureaucracy of contemporary U.S. society (“Intersectional Burdens”). This burden takes the form, for example, of struggling to figure out how to make a doctor’s appointment, to restore or maintain program benefits, or to otherwise deal with a bureaucracy that treats them as unworthy and undeserving. Because this burden is more likely to be experienced by those who are facing racial discrimination, financial struggles, and other systemic hardships, it again works to magnify inequalities during a crisis.
These conclusions are based on relatively small AVP samples (given that transcription was incomplete) and should of course be revisited with larger samples that would allow us to better understand when survey, administrative, and immersive-interview data yield consistent or inconsistent results. The articles in this issue suggest, however, that conventional monitoring methods (such as poverty measures, unemployment rates, food insecurity measures) would be usefully supplemented with a permanent AVP-styled platform that would provide critical supplementary evidence on how low-income households are faring in a crisis-rich world. This two-platform approach would not only help us pick up economic distress as new challenges emerge but may ultimately make it possible to build better quantitative measures that capture distress more completely.
An Emerging Detachment Crisis?
The articles in the preceding section speak to the AVP’s capacity to monitor how people are coping with a known set of crises. If the AVP could also be used to pick up early warning signs of new and emerging crises, that would of course be another important asset. Although it is obviously unfair to expect the next big crisis to be instantly uncovered by one of the small handful of contributors to this volume, it is nonetheless of interest to discuss some of the more troubling findings that have emerged in the early contributions and that arguably provide hints of emerging crises.
The two articles in the emerging-crisis section of this issue are usefully grouped because they converge on the worry that structurally disadvantaged populations have become profoundly disaffected. The first of these—authored by Katherine Cramer, Elizabeth Youngling, and Clinton Rooker (2024; this volume, issue 4)—describes the emergence of a low-income population that feels isolated from mainstream society and buffeted by economic and administrative forces beyond its control (“The Political Implications of Economic Lives”). This is expressed as a sense of futility about getting a decent job, a limited “capacity for interest in politics,” and a limited “sense of agency or responsiveness from institutions of any type.” As the authors describe it, the outside world becomes a blurry amalgam of institutions (government, workplace, benefits providers) that low-income people do not understand, tend to view as very distant from them, and are lumped together as a “faceless, amorphous force.” This blurring is so profound that one interviewee referenced all government institutions vaguely and generically as “they or them.”
The second article in this section, authored by Reuel Rogers (2024; this volume, issue 4), describes another structurally disadvantaged population—urban and suburban Black Americans—that is likewise struggling with profound disillusionment (“The Black Suburban Sort”). The interviews discussed in his article reveal a deep resignation about ongoing crime and violence, hopelessness about the prospects for racial justice, and a broad “democratic fatigue.” As one respondent put it, “I’m numb to it.” When queried about politics, respondents would provide such responses as “I’d rather not talk about it,” “it’s like repetitive suicide,” or “what can I do personally to make a difference?” For this group, there is again an overriding feeling of detachment, spawned by repeated disappointments rather than an incapacity to engage (for a related interpretation, see Thomas et al. 2024, this volume, issue 4).
The upshot is that, although both articles clearly reference the rise of detachment, they rely on different mechanisms that then affect different subpopulations. The detachment that Rogers describes stems from the disillusionment that comes of repeated political failures to address abiding racial inequities, whereas the detachment that Cramer, Youngling, and Rooker describe stems from ongoing personal buffeting by distant and foreign institutions (welfare organizations, government, labor markets). These two forces, as important as they are, may of course be joined by many others that can create isolation and hopelessness (crisis fatigue, rising normlessness, rising addictions, declining fertility) and bring about a wide-ranging detachment crisis.9 The two articles in the disillusionment section provide in this sense an early warning that our nation’s many social problems may have become too overwhelming for too many.
Classical Interpretive Studies
We have also read the contributions for insights into whether scholars can successfully carry out immersive-interview analyses resting on inductive interpretation of themes. This interpretive form—long the backbone of immersive-interviewing research—is of course an important success story within contemporary social science, as evidenced by its growing popularity (Thelwall and Nevill 2021). In building the AVP, many of our (friendly) critics worried that classical interpretive analysis would be compromised, as AVP researchers are no longer engaged in data collection and must therefore forgo the usual back-and-forth between interviewer and interviewee. The AVP leadership team is currently building plans for a permanent immersive-interviewing platform that will allow researchers to carry out follow-up interviews with sample members. Because this would only be viable for research teams that could afford to purchase such interviews, our assumption is that a minority of researchers would have the funds needed to avail themselves of that option. It is important, then, to ask whether a high-quality secondary analysis can be carried out without that follow-up.
The five articles in our classical interpretive methods section make it clear that high-quality secondary analysis is feasible in some cases, but that follow-up interviews are likely to be invaluable in others. The first article, a study of attitudes toward vaccination during the initial rollout period, reveals that views are not nearly as polarized as the survey-based research literature would have it (“Discourses of Distrust”). The authors of this piece—Amy Casselman-Hontalas, Dominique Adams-Santos, and Celeste Watkins-Hayes (2024; this volume, issue 4)—show that negative experiences with the American health-care system are so widespread that pretty much everyone is skeptical about the institution, including liberals who are typically represented as trusting medical science uncritically. The second article in this section, an analysis of health care within the Latinx population, provides a rich description of barriers to access that substantiates some of the key conclusions in the literature (“Can’t Buy Me Health-Care Access”). The author, Josefina Flores Morales (2024; this volume, issue 4), also points to problems that haven’t been adequately appreciated by prior scholars, such as an extremely high level of medical mistrust within the Latine population (attributable, in part, to misuse of pain medications). The third article, a study of platform-based gig labor by Brandon Jackson (2024; this volume, issue 4), reveals that motivations for engaging in gig work go beyond the usual accounts (need for immediate cash, attractiveness of flexible hours) featured in survey-based research (“Motivated by Money?”). Although lower-income workers are indeed typically driven by frequently emphasized supply and demand forces, Brandon Jackson shows that higher-income gig workers often sought gig work simply because they enjoyed the opportunity to learn about their neighbors and neighborhoods. The latter workers noted, for example, that it’s interesting to see what people are ordering, to visit new neighborhoods, and to meet new people. The fourth article in this section, an analysis of housing insecurity by Max Besbris, Sadie Dempsey, Brian McCabe, and Eva Rosen (2024; this volume, issue 4), lays out the many ways that housing-insecure people dealt with the new challenges of the pandemic (“Pandemic Housing”). Although one might have thought that new coping strategies would have emerged, they instead find that those in precarious circumstances mainly fell back on such long-standing strategies as doubling up, seeking public benefits, and turning to friends and family (as well as weaker ties). The final article, by Priya Fielding-Singh, Elizabeth Talbert, Lisa Hummel, and Lauren Griffin (2024; this volume, issue 4), complements the large quantitative literature on pandemic caregiving with a tight qualitative study (“Caregiving in a Crisis”) showing that working mothers with middle-class jobs found it especially difficult to deal with school closures and to continue delivering tightly curated extracurricular activities for their children (music lessons, playdates, soccer practices). Among middle-class households, stay-at-home mothers were able to adapt to pandemic-induced reductions in schooling and extracurricular opportunities, whereas working mothers found it much harder to continue engaging in “concerted cultivation” and reported much stress, worry, and frustration as a result.
We obviously cannot do justice to these studies here. For our purposes, it is mainly relevant that they show that secondary analysis can often deliver new and useful results, even without the benefit of follow-up questioning. The AVP analyst is, in effect, trading off the loss of follow-up questions for the extra information gleaned across the many domains in AVP’s protocol, a trade-off that some contributors explicitly noted and found attractive (Besbris et al. 2024, this volume, issue 4). As true of all omnibus datasets, the AVP’s sweet spot is either a research topic that is well covered within the confines of the protocol (such as the AVP’s coverage of work, poverty, and family), or one that is more shallowly covered but benefits richly from the breadth afforded by an omnibus approach. The early evidence suggests that an ample range of projects falls into one of these two categories. This is obviously not to suggest that all questions are fully answered even among projects within this sweet-spot zone. As with studies using quantitative omnibus datasets, the studies in this issue sometimes advance the field as much by identifying what needs to be known as by securing definitive results.
Finding Hidden Populations
In our introductory comments, we suggested that yet another sweet spot for the AVP is its capacity to secure low-cost representative samples of people who are derogated, stigmatized, or otherwise excluded from mainstream society. Although qualitative research has long been built around a commitment to listen to and learn from excluded or marginalized populations, it has sometimes been difficult to live up to that commitment because many such populations are hidden from view and costly to sample without resorting to convenience samples. The purpose of this section is to examine how our contributors took advantage of the AVP’s capacity to construct a probability sample of small subpopulations. We have included two articles in this section illustrating how hidden populations can be teased out, but in fact many others could have been included in this section as well. For example, many contributors exploited the AVP’s capacity to analyze small intersectional populations (involving intersections of racial, gender, economic, or other identities), but it is presumably unnecessary to review this very important AVP asset because it is quite an obvious one.
We have instead selected two studies that reveal how the AVP can be used to find subpopulations that are not readily identified (hidden populations). In our first illustration of this approach, Corey Abramson, Zhuofan Li, Tara Prendergast, and Martín Sánchez-Jankowski attempt to identify those who are experiencing extreme pain, a more daunting task than one might think (“Inequality in the Origins and Experiences of Pain”). The usual approaches to taking on such a problem clearly fall short. If one proceeded by partnering with a hospital, the resulting sample would only pertain to those who are being treated for pain. If one resorted to a convenience sample and advertised for interviews with those in pain, the resulting sample would likely overrepresent those who constructed their identities around pain and suffering (and would no doubt be unrepresentative in all manner of other ways). If one sought to draw a sample from online panel sources (Qualtrics, Prolific, AmeriSpeak), a complicated and expensive set of filter questions would be needed to ferret out those who fall into the sample. These are, then, all unattractive or costly options. The AVP, by contrast, opens the opportunity to draw a probability sample (without any cost to the secondary analyst) that solves all such problems at once by simply searching for respondents who discussed pain during their interviews. Although these discussions could happen in the course of conversations about health and health challenges, they could also come up when discussing work histories, family relations, or any of the other domains covered by the AVP’s omnibus protocol. Using this sampling approach, Abramson and his coauthors are able to build a comprehensive map of the social organization of pain and then examine the extent to which pain comes up in everyday conversation, the types of pain inequality that emerge, and the ways in which culpability is featured in discourse about pain and misery.
The second example featured in this section is an article by James Hiebert, Lillian Kahris, and Kristin Seefeldt (2024; this volume, issue 5) on disability and work in the United States (“Making Sense of Health-Related Labor-Market Exits and Disability”). The purpose of their article is to understand the often-stigmatized (and partly hidden) population of people who have withdrawn from the labor market for health reasons. We might again ask how a qualitative scholar would go about sampling from this population. If the scholar proceeded by soliciting interviews from those receiving disability benefits, the resulting sample would exclude those who were ineligible or did not apply for such benefits, a potentially very important omission. If the scholar instead proceeded by advertising for a convenience sample of interviews with those who experienced a “health-related labor-market exit,” it would be unclear how that filter was understood by potential respondents and how other selective processes might bias the sample. If the scholar contracted with any standard survey house to draw a probability sample, the cost would be prohibitive. The AVP again cuts through all these problems and allowed Hiebert, Kahris, and Seefeldt to draw the requisite probability-based sample by using the AVP survey to select those not working and then reading through the resulting transcripts to determine whether health problems figured in the withdrawal. After doing so, they then scoured the interviews to determine whether people embraced the identity of disabled, interpreted it as a transition rather than an identity, dismissed it as label assigned to them by others, or rejected it altogether. The resulting study reveals—very compellingly—that people only rarely embrace the identity of disabled even when they are receiving disability benefits or struggling with severe health problems.
We have dwelled on these two articles because they nicely illustrate the potential of the AVP to open a new window for understanding populations that are marginalized, stigmatized, and rarely heard. Because it is typically very expensive to access these populations, they have either been ignored altogether or studied via unrepresentative samples. The AVP resolves this long-standing problem by offering a large representative pool that can be flexibly culled to pull out small hidden populations in automated ways.
Omnibus Analyses
We have noted the various research opportunities that are opened up with an omnibus dataset, but have not yet fully discussed whether our contributors have taken advantage of them. Have the contributors exploited the full information available across various key institutional domains (family, education, work, religion, politics) in the AVP interviews? This section of the issue includes four articles that have explicitly drawn on the omnibus structure of the AVP data. Although many other contributions also relied on cross-domain analyses and could have been included as well, these four will suffice to illustrate the payoff to an omnibus approach. We anticipate that many future studies with the AVP data will likewise rely on its omnibus structure.
The distinguishing feature of these articles is a conceptual interest in understanding the cultural logics that order people’s lives. Because these are deep logics, a common conceit is that they will express themselves across a range of life domains, but that is of course a testable assumption that, as we will see, is not always borne out. The second distinguishing feature of these articles follows directly from the first. Because the shared objective is to discern the abstract logics that inform people’s lives, it is natural to turn to computational methods (machine learning, natural language processing) that can be readily tailored to ferreting out such logics. Although computational methods thus figure prominently in these pieces, the authors also use interpretative methods to validate and make sense of those abstractions.
In the first of these articles, Michael Sauder, Yongren Shi, and Freda Lynn (2024; this volume, issue 5) examine how people understand the role of luck, merit, and structural forces in determining their own life trajectory (“Multiple Meritocracies”). It would be conventional to address such a question with a survey item providing a preset menu of responses to a query about the importance of merit in getting ahead. Because such survey questions may evoke stock or socially acceptable responses, Sauder, Shi, and Lynn proceed instead by analyzing the manifold accounts about social mobility that emerge organically while telling one’s story. By analyzing these on-the-ground accounts, they are able to show that their inner logic is rarely consistent with a vulgar meritocratic view that comes out of survey-based analysis. To the contrary, they find that most everyone understands that their lives reflect a complicated admixture of merit, structural barriers, and contingencies, although there are differences of emphasis in the types of structural barriers that are privileged (as well as the extent to which they are emphasized). In another analysis that exploits the AVP’s omnibus format, Shira Zilberstein, Elena Ayala-Hurtado, Mari Sanchez, and Derek Robey (2024; this volume, issue 5) examine the extent to which people view themselves as agentic, as opposed to being passively buffeted by structural forces (“The Self in Action”). Although the conventional hypothesis is that privileged people are more likely to view themselves as agentic, the authors show that all people, including those who are less privileged, tend to view themselves as agentic in some situations and passive in others (or even to subtly intertwine both types of sentiments in the same situation). This approach again exploits the AVP’s omnibus format by examining how agency and passivity surface across a wide variety of domains and settings. The third article in this section, by James Chu and Seungwon Lee (2024; this volume, issue 5), uses the AVP’s omnibus format to show how people judge and evaluate others across a variety of social contexts (“How Americans Judge”). The main finding is that, when praising family and friends, some people consider whether they are warm or likeable (prosocials) whereas others consider whether they are competent or talented (meritocrats). By contrast, this divide between prosocials and meritocrats recedes in importance when public-sector actors (police, teachers, politicians) are being judged, perhaps because the public sector imposes norms of judgment that mute the particularism of more intimate engagements with family and friends. The final article in this section (“Talk of Family”), a provocative piece by Jessica Hardie, Alina Arseniev-Koehler, Judith Seltzer, and Jacob Foster (2024; this volume, issue 5), follows people as they move through the various institutional domains in the AVP protocol (work, religion, health, criminal justice) and asks whether their families are prominently mentioned in these discussions. This analysis provides a new approach to understanding the extent to which people’s lives are enmeshed in and focused on family.
The preceding articles thus exploit the omnibus protocol by uncovering logics that reflect generalized habits of the heart rather than situationally specific ways of acting, judging, or interpreting. The resulting measures of meritocratic, agentic, prosocial, and familistic logics may be understood as competitors to conventional survey-based items that are secured by asking respondents to directly summarize their behavior or sentiments across many settings. When, for example, a survey respondent is asked whether they behave agentically, they are presumably expected to play back in their minds their manifold engagements in manifold settings, ferret out how agentic they have been in each of them, and then calculate the cross-engagement average. Because that is a cognitively demanding operation, one could forgive a respondent for forgoing it and instead falling back on well-rehearsed stock answers. This line of reasoning implies that, rather than asking respondents to rewind, ferret out, and average, we are better off asking them to recount their engagements directly, just as the AVP’s omnibus protocol does, and then rely on an algorithm to perform the requisite analysis and averaging on the resulting raw data. The AVP thus opens up the possibility that the various habits of the heart currently ascertained through survey items may be more successfully operationalized and monitored through immersive interviewing.
LIMITATIONS
The analyses in this issue suggest that the AVP is largely delivering as we had hoped it would. The contributors have provided new evidence on the key crises and developments of our time, uncovered hints of new crises in the making, shown that high-quality interpretative analysis does not always require follow-up interviewing, culled important hidden populations from the AVP’s large pool of interviews, and used the omnibus form to develop a new suite of measures that may outperform conventional survey-based measures. Although we are heartened by this early round of results, it would of course be unwise to reach any conclusions about the AVP’s payoff until additional waves of research using the full dataset are completed.
In carrying out our stock-taking exercise, it is also useful to consider the various concerns of our reviewers and commentators, some of whom have not always been fully convinced that a public immersive-interviewing platform fills a pressing need. The AVP team has engaged frequently with such commentators and critics by hosting AVP conferences, AVP briefing sessions, and various meetings with our trial users and other leaders in the field. We have also benefited greatly from the reviews of this article and the many AVP grant proposals that have been submitted. Although the feedback that we have received in these various ways has sometimes been critical, it has almost always been constructive in ways that have led to important improvements to the AVP methodology. Because the possibility of establishing a permanent immersive-interviewing platform is currently being discussed with leaders in the field, it is especially important to take stock of criticisms relevant to these discussions. The purpose of this section is to do just that by rehearsing the most common criticisms, discussing whether they are on the mark (as dispassionately as we can), and considering whether a future AVP fielding could and should address them.
Criticisms of the Protocol
It is useful to begin by addressing the complications that arise when one seeks to build a public-use platform within a field that has historically focused on individualized data collection and research. When a protocol is designed to serve a wide range of research purposes, the stakes are high and the decisions fraught because public money is being expended in ways that affect what types of research can be undertaken and what will or will not be discovered. It is understandable, therefore, that an important swath of concerns have emerged around the proper scope of the AVP protocol, how it is vetted, and how it can be modified and revised. We will present these critiques by directly paraphrasing some of our reviewers and commentators because they have stated them in nicely direct and pithy terms. These critiques, which are set off as extracts, are followed by our responses.
The protocol’s reach: “Although the AVP protocol covers the interviewee’s everyday interactions with important institutions (e.g., the family, neighborhood, workplace), many aspects of everyday life aren’t touched upon in the protocol and can’t be addressed via an AVP analysis. The AVP protocol is too narrowly circumscribed to substitute for conventional privately-collected datasets.”
We have led with this line of criticism because it gives us another opportunity to stress that a public immersive-interviewing platform can only complement—but never replace—the immensely valuable individualized research form. Because the immersive-interviewing method has been so productive and successful, our goal is simply to expand its footprint by building a complementary public-use form that can be used whenever researchers address questions within the AVP’s core data zone. The AVP’s goal is to cover everyday life and sentiments in those institutions (the family, the workplace, and the neighborhood) and cultural domains (religion, politics, identity) that are central to contemporary life and are thus useful gateways to understanding how people live, what they are thinking and feeling, and how they are making sense of their lives. This approach nonetheless leaves much important terrain unexplored; indeed, just as analyses of GSS’s core data zone can never replace all the critical quantitative analysis occurring outside this zone, so too analyses of AVP’s core data zone will always be but a small complement to the vast amount of immersive-interviewing and related research occurring outside this zone. Although the data zone covered by the AVP interview is thus limited in size, the goal is to broaden it in future AVP fieldings by regularly rotating in special modules that address unfolding crises, emerging topics of interest, or other critical new content.10 The most important job of the AVP’s future advisory board will be to guide the development of the full protocol and to oversee open competitions for the special modules (modeled after the GSS’s special module competition). This oversight function entails assessing whether the existing prompts are performing well, testing and evaluating possible new prompts, and otherwise balancing the competing needs for continuity and updating. Because the advisory board is all-important in this sense, it is of course critical that it is broad and diverse, that it represents a wide range of research constituencies, and that it secures input throughout the planning process from all relevant communities and stakeholders.
The differentiation of data collection and analysis: “The AVP has installed a division of labor between data collection and data analysis that prevents researchers from pursuing promising leads or otherwise following up with interviewees. Without this follow-up capacity, the analysis may be shallow and many fundamental questions may remain unanswered.”
This concern may be understood as an analog to the common lament among survey analysts that an important causal variable is unavailable in the survey of interest. The standard response to this problem—indeed it is the go-to mantra of all graduate-student advisors—is that survey users should choose to undertake an analysis that is feasible rather than opting for one that is not. Within the AVP context, several of our early users likewise opted to change their research question when they discovered that their original one could not successfully be taken on, a type of problem-selection pragmatism that is the unfortunate cost of doing business in the world of public-use datasets (see Besbris et al. 2024 for an insightful discussion of this point). This is not to gainsay the equally important point that, had follow-up interviewing been made available within the AVP platform, a broader swath of topics could have been examined by combining existing interview material with new probes. Because our critics have been quite convincing on this point, we have built concrete plans for installing a new follow-up capacity whereby interested researchers can contract with the AVP’s data-collection organization to carry out reinterviews in future fieldings. This innovation will allow researchers to garner new evidence on possible mechanisms or interpretations, take on puzzles that the original interviews left unresolved, or otherwise exploit the power of reinterviewing. Although researchers can always resort to the usual alternative of mounting their own independent study, the virtue of this new design is that it would exploit the existing probability sample and the existing data already available from the original interview.11
Community engagement: “The AVP research process seemingly runs counter to the growing commitment among social scientists to develop relationships with the communities involved in their studies (i.e., “community-engaged scholarship”).”
This critique arises because of the prohibitively high costs of engaging with each of the many communities that serve as secondary sampling units (SSUs) within our national study. Before the pandemic broke out, the AVP interviewers formed small teams that moved from one SSU (census block groups) to the next, a design that allowed them to form relationships with community leaders. We also relied heavily on our Federal Reserve Bank partners to engage with communities in their catchment areas. These relationships were, however, mainly forged after the protocol was developed (and did not, therefore, inform the contents of the protocol itself). In future fieldings of the AVP, engagement with individual SSUs will likely be even more limited (given the high costs of SSU-specific engagement), and other approaches to ensuring a participatory research design will have to be taken. Because it may not be possible to engage with representatives from each of the hundreds of SSUs in future fieldings, it will be especially important to include representatives of the different types of SSUs that are part of the study (such as rural, deindustrializing, or gentrifying SSUs). It is also critical to recognize that many types of communities—not just spatially defined ones—are important to engage. The advisory board for future AVP fieldings should accordingly be charged with building the protocol in collaboration with representatives of all key communities (as defined by race, ethnicity, gender, community type, and other identities), and additionally carrying out cognitive testing across this wide array of groups (with such testing ensuring that the prompts are interpreted as intended and thus provide a valid vehicle for expression). The latter commitment to rigorous cognitive testing, which qualitative scholars do not always undertake, is especially critical given the AVP’s interest in properly representing and interpreting the voices of everyone. At the same time, many qualitative scholars who collect their own data are committed to trialing their initial research conclusions and interpretations with community members (and then revising their interpretations as necessary), an approach that secondary users of public-use datasets would do well to emulate. When the full public release of AVP data occurs, we plan on hosting a regular series of AVP conferences that will include not just scholars but also a wide range of community representatives. If this hybrid conference form proves to be successful, we hope that it will be adopted in future AVP fieldings as well.
Criticisms of Probability Samples
The AVP team has also encountered criticisms suggesting that probability samples are not always as useful as they are made out to be. Before we turn to two very reasonable worries about probability samples, it is important to first dispense with a worry that is frequently expressed but based on a misunderstanding of probability sampling. We refer here to the argument that scholars who analyze subpopulations (such as Asians, single adults, or sports fans) of a national probability sample cannot treat those subpopulations as probability samples themselves. This is an incorrect conclusion (see DeLuca 2022). The great benefit, to the contrary, of a national probability sample is precisely that it does yield spinoff probability samples for any subpopulation within the original sample. This means that researchers interested in a subpopulation analysis within the AVP can secure all the benefits of a probability sample without having to draw one on their own.
The AVP thus makes it possible to draw hundreds of subpopulation probability samples at no cost to the secondary user. As attractive as this sounds, our critics have suggested that this theoretical benefit may not always be available in practice, given that many subpopulations of interest are either small or hidden. We discuss each of these two problems in turn.
Small populations: “In many cases, researchers wish to study very small populations, like people in a small town, people who have a rare disease, or people who are members of a fringe political or religious group. The AVP is quite unuseful in these situations.”
This critique makes the important point that, whenever a researcher has an intrinsic interest in a very small population, the AVP will not be useful because it will not have enough—or perhaps any—cases within the population of interest. Because this point is uncontroversial, we have relatively little to add. We simply reiterate that the AVP, like the GSS and other omnibus public-use datasets, was never designed to replace very valuable existing forms of research that are able to target extremely small populations. The only supplementary point we would make is that sometimes a study site, such as a deindustrializing town, is chosen not because of an intrinsic interest in that particular site but because it is viewed as a convenient vehicle for examining how small-town deindustrialization plays out more generally, how workers cope with deindustrialization in a small-town setting, or some other more generic question about deindustrialization. It is not uncommon to choose sites precisely because they are exemplars in this sense. When that is indeed the case, a large-population study is in effect masquerading as a small-population one, and an AVP-based analysis might well be feasible and useful, but only insofar as the analysis in question does not require a large observation-per-site ratio.12 The researcher might, for example, proceed by pooling interviewees across all deindustrializing sites in the AVP rather than carrying out a case study of one such site. If doing so still failed to yield an adequate sample size, the researcher could also consider pooling across multiple fieldings of the AVP.13 This approach can open up many attractive opportunities to understand important—albeit small—subpopulations without having to resort to nonprobability samples. If a researcher pooled, for example, five annual AVP samples (with two thousand observations per year), they could expect to find approximately one hundred people who identify as transgender (USA Facts 2020), approximately fifty-five affiliates of Jehovah’s Witnesses (PRRI 2021), approximately 550 believers in QANON (Uscinski et al. 2022), and approximately ninety users of methamphetamines (National Survey of Drug Use and Health 2021). Although it is often argued that very small groups of this sort can only be studied via nonprobability samples, the AVP opens up an important alternative approach that allows for generalizations to known populations.
Hidden populations: “The AVP cannot be used to study hidden populations unless interviewees are explicitly queried about their membership in the population of interest. Moreover, whenever the group of interest is stigmatized (and many hidden populations are of course stigmatized), even a direct query won’t get the job done because interviewees may be reluctant to discuss the relevant identity or behavior.”
This second critique again takes aim at the practical usefulness of the AVP in studying small populations that are hidden because they are not based on a frequently adopted identity (of the sort that might be ascertained in, say, the AVP’s follow-up survey). The subtext of this critique is that, although the AVP has the theoretical capacity to generate probability samples of important hidden populations (such as conspiracy theorists), in practice it is very difficult to ascertain members of these populations without including an explicit query about membership (such as “are you a conspiracy theorist?”). If this claim were generally true, it would reduce the usefulness of the AVP because the protocol would need to anticipate all the subpopulations of interest and then query systematically about each of them. We are not convinced, however, that this identities-must-be-queried claim is indeed true. The main reason we are unconvinced is that many AVP authors have been able to successfully identify hidden subpopulations by searching for relevant markers within the interviews. These scholars have shown, for example, that the AVP interviews can identify conspiracy theorists (Bauvois et al. 2023), those experiencing severe pain (Abramson et al. 2024), those too sick to work (Hiebert, Kahris, and Seefeldt 2024), and those who have experienced a sexual trauma (Caputo et al. 2024). We do of course need to worry about false negatives. It is possible, for example, that those who do not engage in conspiracy talk within an AVP interview are in fact conspiracy theorists but are reluctant to talk about it because it is stigmatizing. To address this worry, the gold standard approach would be to draw a subsample of AVP interviewees who do not engage in conspiracy talk, and to then follow up with a reinterview that uses best-practice prompts to draw out possible shy conspirators (using the new follow-up capacity discussed). Although this gold standard approach has not yet been deployed within the AVP context, it is at least reassuring that the existing AVP-based rates of conspiracy talk, severe pain, sexual trauma, and health-induced withdrawals largely comport with rates from other trusted sources. It is thus plausible that, because the AVP interview adopts well-tested approaches to reducing stigmatization (such as normalizing all responses to prompts), a gold standard approach might not yield all that many false negatives. This is not to question the importance of directly testing that conjecture by estimating the number of false negatives when the AVP’s new follow-up capacity is installed. The results from such tests will not only provide high-quality evidence on stigmatized behaviors but also could be used to improve the AVP’s existing methods for enabling open, honest, and judgment-free conversations.14
Criticisms Pertaining to Analytic Complications
The last set of worries pertain to the various data-processing complications that arise when analyzing large numbers of immersive interviews. Because our trial users were entering uncharted territory, they faced a host of problems that the AVP team had only imperfectly anticipated, many of which had to be solved on the fly and often quite imperfectly. We are immensely grateful for their patience in working through these complications. It is useful to share some of the data analytic concerns that they or our reviewers raised and discuss how these concerns might be addressed with new software and methods for large-N qualitative datasets.
Industrial-sized analysis: “Although a large-N dataset may be useful for analysts using computational methods, the payoff is less clear for those using classical interpretive methods. It’s simply impossible for a single scholar—or even a modestly-sized team—to process all the interviews that are now available.”
The AVP leadership team had not, we have to confess, anticipated this concern. We instead worried that the AVP sample was too small to meet the needs of scholars who wished to locate hidden populations, to carry out intersectional analyses, or to use data-intensive computational methods. It was a mistake on our part to fail to appreciate that many scholars found the AVP attractive not because it could be sliced and diced into various subpopulations of interest but because its underlying probability sample made it possible to generalize to the U.S. population while still using classical interpretative methods. For these scholars, the large sample that was part and parcel of the AVP design was a mixed blessing, as it simply took too long to read, hand code, and digest all the interviews (even with the luxury of modestly sized teams of analysts). In most of the early AVP analyses, this complication was sidestepped because the research began before all interviewing or transcribing was completed, and the available sample was therefore relatively limited in size.15 Because a large sample now is available, it is clear that improved software is needed to support large-N qualitative analysis, software that makes it possible to work efficiently with large coding teams, that allows for crowdsourced coding, and that supports mixed-methods analysis (at the individual level) more seamlessly. Even with such tools, scholars who prefer to work alone or in small teams may choose to draw a random subsample of interviews insofar as they wish to generalize to the U.S. population, thereby reducing the amount of reading and coding without any sacrifice of representativeness. It may also be useful to deploy analytic approaches that qualitative researchers have designed to reduce the cognitive burden of analyzing larger datasets or to exploit large language models (LLMs), natural language processing (NLP), and various automated coding regimens.16 Whenever researchers have explicit hypotheses in play, they can also use power tests to settle on the requisite sample size in advance, an approach that eliminates the intrinsic subjectivity (and resulting bias) of asking the analyst to decide when saturation has been reached. Although we are unconvinced, therefore, that industrial-sized analysis is an intrinsic problem, we do of course agree that qualitative software needs to be upgraded to work more seamlessly with large numbers of cases, large research teams, crowdsourced coding, and individual-level mixed-methods data.
Weights and classical interpretive analysis: “The AVP weights are of course useful for those using quantitative computational methods, but it’s unclear how to use them within the context of classical interpretive analysis. If interpretive scholars opt to simply ignore the weights, they cannot any longer safely generalize to the population of interest, thereby losing one of the main payoffs to an AVP analysis.”
The AVP data come with precalculated sampling weights because the AVP sampling design incorporated an oversample of some subpopulations and because response rates among those selected into the sample differed across subpopulations. We also provide AVP users with the data fields needed to adjust for clustering and other sampling design features. For scholars carrying out quantitative analyses of the AVP data, no special or unusual complications thus arise. The interpretive analyst, by contrast, does not have the benefit of best-practice guidelines that help them exploit the representativeness of the AVP data. At the data analysis stage, the interpretive scholar of course wants to be able to learn from the data in unbiased ways, ideally exploiting sampling weights to that end. In this context, the separation of data collection from data analysis is potentially an asset because it makes it possible to develop data-delivery software that feeds interviews to the analyst in ways that offset known bias-inducing dynamics, such as confirmation bias. We could imagine, for example, interview-delivery software that uses sampling weights to correct for nonresponse bias when delivering interviews to analysts (meaning that interviews with, say, a weight of 2 would be twice as likely to be pushed out to the analyst). In this way, analysts are delivered a representative experience as they read the interviews, thus reducing the risk that nonresponse bias or chance clustering of certain types of interviews installs an improper prior that is then hard to overcome. For scholars who prefer to use a saturation rule, this approach would ensure that judgments about saturation are not affected by an unrepresentative feed, thus reducing at least some of the subjectivity associated with this rule. This approach could similarly be applied at the subpopulation level to ensure that a representative sample is delivered and then experienced within each of the groups of interest. We are not of course suggesting that the foregoing example solves all problems or that it is in any way straightforward to overcome the host of cognitive biases that affect interpretive analysis (and all other forms of analysis). We are instead suggesting that public-use datasets offer important opportunities to experiment with possible approaches, to assess their bias-reducing effects, and ultimately to develop software and analytic approaches that improve the quality of social science research.
CONCLUSIONS
During the build-out of the experimental AVP platform, a fair number of AVP skeptics worried that there would not be much demand for the data, a worry that is quite reasonable given that collecting one’s own data is deeply built into the immersive-interviewing field and serves, in effect, as a rite of passage. We are gratified, in light of this worry, that the response to our open call attracted the second-highest number of applications in this journal’s history. Because applicants were so numerous, we had to open a second tranche of trial analyses, and many promising results from that second tranche are now appearing. We are grateful to all our early users in helping us prepare for the full rollout and for providing critical early evidence on the payoff to the AVP.
As discussed, the AVP also has garnered its fair share of criticism, although arguably the amount of criticism in play is quite modest for a field infamous for contention. The criticisms that have been proffered have almost invariably been constructive and have motivated important improvements to the AVP’s methodology. With these concerns in mind, a large team of AVP advisors is currently consulting with data-collection organizations, government agencies, and possible funders to explore how the experimental AVP is best converted into a permanent immersive-interviewing platform.
As the trial period comes to a close and we move to full dissemination of the experimental AVP, it is worth asking how a permanent platform (one that is continuously in the field and allows for real-time public use) would likely play out. If the early AVP results can be safely extrapolated, one would have to conclude that a permanent platform would have a substantial effect on basic and applied social science, likely a larger effect than that of adding yet another public-use quantitative dataset to an already crowded field of such datasets. This new qualitative platform, because it would be fine tuned for discovery, would send a signal that we care about detecting and monitoring social problems as much as we care about detecting and monitoring natural disasters, such as hurricanes, floods, fires, or earthquakes. The amount of monitoring research would take off; the capacity to detect crises in the making would improve; the high costs of a delayed diagnosis would be reduced; and journalists (and their critics and competitors) would have a real-time probability sample of Americans at their disposal. By exploiting the dark matter of immersive interviews, this new platform would also help us build better predictive models of key outcomes (such as poverty, homelessness, depression) and then use these models to improve social programs and advance basic science. The new infrastructure would likewise give conventional survey-based opinion and attitudinal measurement a run for its money by developing powerful new NLP-based measures of sentiments from the raw material of everyday life (rather than attempting to surgically elicit sentiments by simply asking about them). The AVP platform may also give conventional social media analysis a run for its money by supporting new NLP-based measures of sentiments that are primed in known and controllable ways, that are comparable over time and across subgroups, and that are based on representative rather than highly selective samples. Across all these fields, the new platform would serve as a shared testbed, and a more cumulative form of qualitative work would emerge through increased replication, reinterpretation, and systematic accretion and extension (Weeden 2023). This new field of large-N qualitative work would rapidly grow as students are trained with public-use datasets in high school, college, and online classes, as new types of large-N qualitative analysis software are developed, and as entry barriers are dramatically reduced and open the field to less-resourced scholars lacking the sabbatical time and money needed to collect their own datasets. It follows that this new platform would enrich basic social science, applied social science, and even social scientific journalism.
It is unlikely that this new work, as important as it is, would come at the expense of the very successful individualized form of immersive interviewing. When public-use datasets were introduced into the quantitative field in the 1950s, the corresponding individualized form of quantitative research nonetheless remained strong and prominent, indeed it was periodically reenergized by the introduction of various cost-saving innovations, such as the rise of remote interviewing and the introduction of online panels. The same outcome is very likely within the immersive-interviewing field. It would remain the country’s go-to resource for addressing topics not covered in the public-use dataset, for carrying out in-depth studies that go well beyond what is available in the omnibus protocol, and for capturing hidden populations that are just too small or too vulnerable to be reached with a public-use dataset. At the same time, the public-use form would generate new questions that could only be addressed with one-off studies, thereby further increasing demand for them. The available evidence suggests that the GSS, for example, has had precisely this effect within the quantitative field (Davern et al. 2021). The permanent immersive-interviewing platform currently being planned would also reduce the cost of one-off studies (and thus expand their reach) by allowing for piggyback studies with empaneled AVP respondents. For all these reasons, it is likely that the public-use form will always play a complementary role, serving in effect as a form of brand differentiation that testifies to the larger success of immersive-interviewing research.
FOOTNOTES
↵1. “Crises,” he emphasized, “are times when economics and economists can and should really prove their worth” (Krugman 2012).
↵2. There are of course many social scientists who have engaged in after-the-fact interpretations of political extremism. See, for example, Arlie Hochschild, Strangers in their Own Land: Anger and Mourning on the American Right (2026); Katherine J. Cramer, The Politics of Resentment: Rural Consciousness in Wisconsin and the Rise of Scott Walker (2016). We are not suggesting that such after-the-fact monitoring does not happen but only that a richer trove of real-time data would assist in carrying out that type of monitoring.
↵3. Although the proportion of economics research that relies exclusively on immersive interviewing is still relatively low, it is becoming more common for economists to include an immersive interview component in studies that are primarily quantitative (see Thelwall and Nevill 2021; Bergman et al. 2020).
↵4. It should be stressed that many qualitative researchers are uninterested in generalizing to a known population (see Small and Colarco 2022; DeLuca 2022).
↵5. Interviewers were instructed to continue probing until expenditures and income were reconciled to within $50, a method pioneered by Kathryn Edin and Laura Lein (1997).
↵6. Although some immersive-interview researchers are able to secure the grants needed to collect large representative samples (and to make their data available for secondary analysis), such funding has typically been in very short supply. It is much more common, therefore, for immersive-interview scholars to work within an individualized mode of production that limits the opportunity to collect either a large sample or a probability sample.
↵7. The AVP sample was originally designed to represent the unhoused population and people residing on Native lands. These plans had to be abandoned when the pandemic broke out because it was difficult to reach these populations with a remote interviewing protocol. The AVP leadership team is pursuing opportunities to incorporate these populations now.
↵8. We hope that, by setting new standards for protecting confidentiality in qualitative data, the AVP will ultimately become part of the initial round of demonstration activities of the National Secure Data Service.
↵9. The article by Michael Sauder, Yongren Shi, and Freda Lynn (“Multiple Meritocracies”) also identifies a large swath of Americans who are “indifferent, accepting, disengaged, apathetic, or alienated.”
↵10. We experimented with this special module approach in the original fielding as well by adding new prompts in response to the Black Lives Matter movement, the early pandemic shelter-in-place orders, the highly contested vaccination rollout, and the storming of the Capitol.
↵11. Although we are very excited about installing this follow-up capability, it bears emphasizing that the vast majority of immersive-interview studies have relied on one-off interviews rather than repeated interactions (between interviewer and interviewee). The opportunity for follow-up interviews may nonetheless prove more valuable within a public-use context because the first-round interviewers may not have probed in ways that the secondary user would have (as the first-round interviewers were not likely animated by the particular research topic being pursued by that secondary user). The best way to determine the value of this follow-up capability is to install it in the next AVP fielding and examine how frequently it is used and to what effect.
↵12. It is important to reiterate here that a pooled AVP analysis of deindustrializing sites would yield very few observations per site and would not, therefore, be viable for any analysis that demands a great many observations per site. If, for example, a scholar sought to undertake a full-network analysis of the effects of deindustrialization, a pooling approach would almost certainly be inadequate to the task (because it would not be possible to represent the full network in any given site). The larger point here is that a great many important research projects require single-site designs of the sort that the AVP could never handle.
↵13. Under current plans for future fieldings, the AVP will be fielded continuously (with four quarterly samples per year).
↵14. Before the AVP was fielded, the interviewers underwent a full month of intensive training, with the last week of that training devoted to trial interviews carried out under the supervision of seasoned interviewers.
↵15. The sampling design for the pandemic-year AVP was based on quarterly samples because this allowed analysts to make inferences about the U.S. population every quarter rather than waiting for all 2,700 interviews to be completed.
↵16. We thank one of our anonymous reviewers for pointing to various exemplar approaches (Timmermans and Tavory 2022; Small 2009) for analyzing large qualitative data sets. These approaches begin with a very small subsample of cases or even a single case and then examine how this subsample (or single case) yields conclusions that may differ from other cases. Because such approaches are labor intensive, LLMs could be harnessed to compare the text of this scholar-selected index case to all other cases in the data set, thereby generating a subset of discrepant cases for further analysis by the scholar. This machine process could be run multiple times with slight prompt variations to provide confidence intervals on the analysis subset that was ultimately chosen. It would also be possible to develop a more thoroughgoing form of LLM-based coding by drawing on coding manuals produced by expert qualitative researchers, passing them to the LLM, assessing the capacity of the LLM to reproduce the coding decisions of human coders on held-out data, and iterating on this process until the LLM passes a threshold of acceptable performance. The upshot is that we are confident that the large-N problem can be addressed via a host of human and automated data-reduction techniques, including, at worst, simply taking a random sample of the data.
- © 2024 Russell Sage Foundation. Edin, Kathryn J., Corey D. Fields, David B. Grusky, Jure Leskovec, Marybeth J. Mattingly, Kristen Olson, and Charles Varner. 2024. “Listening to the Voices of America.” RSF: The Russell Sage Foundation Journal of the Social Sciences 10(5): 1–31. https://doi.org/10.7758/RSF.2024.10.5.01. We are grateful for the comments of Stefanie DeLuca, Mitch Duneier, Shamus Khan, Timothy Nelson, Yu Xie, and the Russell Sage Foundation reviewers. The views expressed are the authors’ alone and do not represent those of any of the organizations with whom the authors are affiliated, including the Federal Reserve Bank of Boston, the Federal Reserve System, or its Board of Governors. Direct correspondence to: Kathryn J. Edin, at kedin{at}princeton.edu; Corey D. Fields, at cdf46{at}georgetown.edu; David B. Grusky, at grusky{at}stanford.edu, Center on Poverty and Inequality, 30 Alta Rd., Stanford, CA 94305; Jure Leskovec, at jure{at}cs.stanford.edu; Marybeth J. Mattingly, at beth.mattingly{at}bos.frb.org; Kristen Olson, at kolson5{at}unl.edu; Charles Varner, at cvarner{at}stanford.edu.
Open Access Policy: RSF: The Russell Sage Foundation Journal of the Social Sciences is an open access journal. This article is published under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.
In this issue




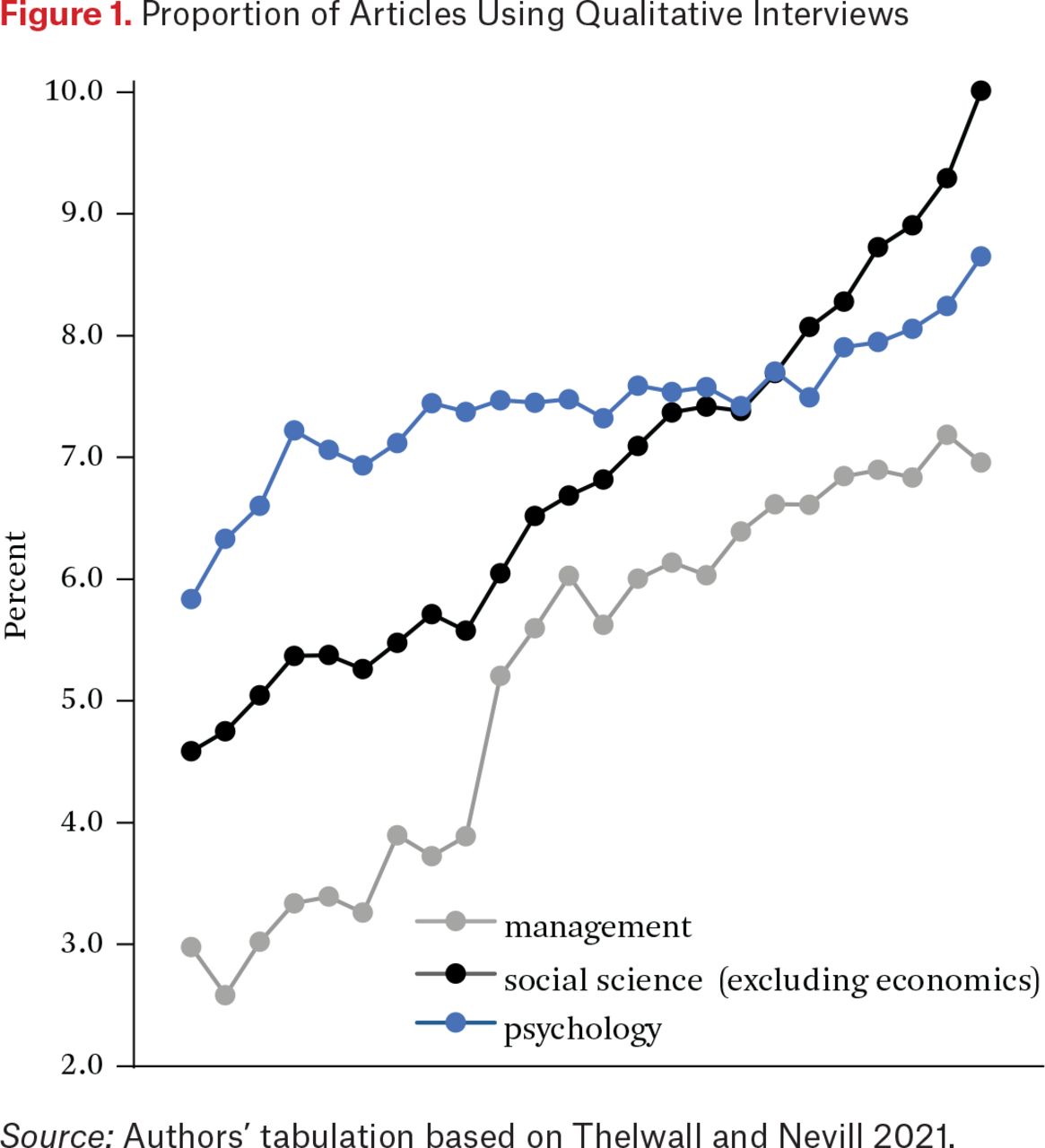{kind=link}
Jump to section
Related Articles
Cited By...
- No citing articles found.