
Abstract
Residential segregation by income and education is increasing alongside slowly declining black-white segregation. Segregation in urban neighborhood residents’ nonhome activity spaces has not been explored. How integrated are the daily routines of people who live in the same neighborhood? Are people with different socioeconomic backgrounds that live near one another less likely to share routine activity locations than those of similar education or income? Do these patterns vary across the socioeconomic continuum or by neighborhood structure? The analyses draw on unique data from the Los Angeles Family and Neighborhood Survey that identify the location where residents engage in routine activities. Using multilevel p2 (network) models, we analyze pairs of households in the same neighborhood and examine whether the dyad combinations across three levels of SES conduct routine activities in the same location, and whether neighbor socioeconomic similarity in the co-location of routine activities is dependent on the level of neighborhood socioeconomic inequality and trust. Results indicate that, on average, increasing SES diminishes the likelihood of sharing activity locations with any SES group. This pattern is most pronounced in neighborhoods characterized by high levels of socioeconomic inequality. Neighborhood trust explains a nontrivial proportion of the inequality effect on the extent of routine activity sorting by SES. Thus stark, visible neighborhood-level inequality by SES may lead to enhanced effects of distrust on the willingness to share routines across class.
Recent evidence indicates that residential segregation by income and education is increasing alongside trends of slowly but steadily declining black-white segregation (Domina 2006; Reardon and Bischoff 2011). Research on segregation patterns, however, focuses almost exclusively on where groups with varying economic statuses live, neglecting potential differences in the range of places people go during the course of their day. As such, segregation research often implicitly assumes that residents of the same neighborhood do not further sort themselves by socioeconomic status in the spaces where they conduct daily activities. Drawing on this expectation, some theories of intergroup contact and policies promoting mixed-income housing claim that residential integration by income and education has a range of benefits because integration extends beyond the walls of people’s homes to the things that people do and the places they go (Jargowsky and Swanstrom 2009; Talen 2006).
Yet, few studies examine the extent of socioeconomic segregation in the activity spaces of neighborhood residents (but see Jones and Pebley 2014; Krivo et al. 2013). Are people with different socioeconomic backgrounds who live near one another just as likely to share routine activity locations as those of similar education or income? Or instead, are the activity locations of socioeconomically distinct households who live in the same neighborhood segregated? Residential propinquity should increase the extent to which individuals of different social classes encounter one another. However, social distance may trump such residential effects and make it unlikely that people with different socioeconomic statuses go to the same locations to conduct activities. No evidence to date evaluates the extent to which socioeconomic differences in households within the same neighborhood influence shared nonresidential routines.
Research is also silent about how household socioeconomic segregation in routine activity locations varies according to the character of the neighborhoods where people live. Drawing on competing perspectives regarding the influence of neighborhood heterogeneity on social interaction, we consider how neighborhood socioeconomic inequality affects the extent to which neighborhood residents from similar and dissimilar classes share activity locations. Extended to socioeconomic status (SES), the contact hypothesis would predict that high levels of diversity increase cross-group trust and social interaction, which should in turn increase the chances of neighbors of different statuses going to the same places (Allport 1954; Emerson, Kimbro, and Yancey 2002; Pettigrew 1998; Pettigrew and Tropp 2006). Alternative approaches, however, argue that neighborhood diversity fosters distrust, leading to either generalized withdrawal (reduced association with all groups) (Putnam 2007), or conflict (reduced trust and association with other SES groups but enhanced solidarity and association with one’s own SES group).
In this paper, we draw on residential and activity space segregation research to develop and test hypotheses regarding the extent of, and variability in, socioeconomic (income, education) sorting in the routine activity locations of urban neighborhood residents. The analyses draw on unique data from the Los Angeles Family and Neighborhood Survey (L.A.FANS) that identify the locations where residents from a representative sample of neighborhoods in Los Angeles County live, work, shop, worship, visit the doctor, and spend other time. Extending p2 models for network data (Zijlstra, van Duijn, and Snijders 2006) to the multilevel setting, we analyze pairs of households located in the same neighborhood (for a sample of sixty-five census tracts) and examine whether the dyads conduct routine activities in the same location (census block group). We then examine the extent to which observed activity location sorting patterns by SES vary across neighborhoods as a function of tract-level socioeconomic inequality and perceived trust. The study’s innovations include use of novel activity space data to estimate the magnitude and multilevel sources of routine activity segregation—a largely neglected phenomenon in extant urban research.
THEORETICAL BACKGROUND
The focus on socioeconomic inequality in where neighborhood residents go stems from growing evidence that residential segregation by income and education is increasing (for example, Domina 2006; Fischer 2003; Massey and Fischer 2003; Reardon and Bischoff 2011). Segregation within metropolitan areas of the college educated from people with low education rose dramatically from 1970 through 2000 (Domina 2006), and the concentrations of poverty and affluence continue to climb (for example, Jargowsky 2013; Reardon and Bischoff 2011). These changes occurred alongside an overall decline in black-white segregation (Fischer 2003; Massey and Fischer 2003). Here, we move beyond analyses of tract-level patterns of integration or segregation to consider expectations regarding the extent to which routine activity patterns are shaped by social (SES) distance between residents of the same neighborhood; and neighborhood-level factors independently contribute to the tendency to share routines and modify the effects of social distance between households. We begin by discussing the potential for household dyad SES effects on spatial sorting in routines and then move to neighborhood effects on shared routines—both direct and through modifying dyad effects.
Household Dyad SES Effects on Shared Routines
An implicit assumption in studies of residential segregation is that identifying residence in a neighborhood (typically a census tract) and describing that neighborhood’s sociodemographic composition captures day-to-day experiences of segregation or integration. Given this assumption, these analyses essentially assume a pattern of random mixing in nonresidential activity spaces. In this approach, households in the same neighborhood do not experience additional spatial sorting in the places they routinely go. Yet, the social structural factors that shape patterns of residential segregation may also operate to segregate routine activity locations such as places of employment, school, worship, child care, medical care, leisure, and other destinations (Palmer 2013). For example, differences in affordability, perceived acceptability, or bias in how people are treated, and information about where to get jobs, services, and other amenities may vary by economic status among residents of the same neighborhood, leading to segregation by SES in where people routinely go. Evidence of spatial sorting by socioeconomic status in routine activities among neighbors would support such notions and challenge the assumption of shared access to local resources (for example, schools, places of employment, and amenities such as parks) implicit in research on residential integration. Yet the extent to which activity spaces are segregated between households with different social characteristics within the same neighborhood is virtually unknown. Examining the degree of spatial sorting by socioeconomic status—a dominant social structural influence on social interaction more generally (Hipp and Perrin 2009)—in the daily routines of residents is a necessary step in understanding the mechanisms through which segregation affects access to resources and life outcomes.
The random mixing model may be seen as a relatively optimistic view—one that underlies mixed-income housing policies that assume residential socioeconomic integration will extend beyond simply living next to one another into the ways that residents spend their day and the places that they go (Jargowsky and Swanstrom 2009; Talen 2006). However, theory and research on mixed-income housing indicate that this may not be the case. Evidence suggests that people of different economic statuses carry out routine activities in different locations even if they reside in integrated neighborhoods (Lees 2008). First, material constraints may diminish the likelihood of shared routines across class. Material constraints limit the places lower-income residents go to shop, work, spend leisure time, and access social support services such as health care or child care due to affordability and accessibility (for example, transportation options). In contrast, higher-SES individuals have the resources to use more expensive services that may be in very different locations than those used by their lower-income counterparts. Further, their greater ability to afford an array of services and transportation costs may lead to a more extensive set of activity locations simply because they have resources to go wherever they want. As such, we hypothesize that higher-SES individuals will have a lower likelihood of contact during activities not only with coresidents of lower status but also with neighbors of any SES as routine activity locations increasingly reflect the unencumbered idiosyncratic preferences of individuals.
Beyond material constraints, social distance between residents of the same neighborhood may limit willingness to share routine activities. Differences in SES between residents may be associated with varying attitudes and lifestyles that could contribute to less willingness to share routines (Arthurson 2010; Kleit 2005; Levy, McDade, and Bertumen 2013; Tach 2009). To the extent that class similarity is associated with a sense of group identity, a preference for sharing routines with those of similar SES may enhance a feeling of belonging and inhibit sharing routines across SES (Hipp and Perrin 2009). Some people of higher status may hold stereotypes regarding the behavior and norms of lower-class individuals that lead them to avoid encounters with those of lower status even if they live near one another (Chaskin and Joseph 2013; Chaskin, Sichling, and Joseph 2013; Tach 2009). Lower-status individuals may also be less inclined to share routine activities with their higher-SES counterparts who live in their neighborhood because they think they might be poorly treated, discriminated against, or made to feel unwelcome (McCormick, Joseph, and Chaskin 2012; Tach 2014). Thus, we expect that the likelihood of shared routine activity locations across SES will be lower than for those of the same SES.
Neighborhood Effects on Shared Routines
We also explore how neighborhood characteristics shape where neighbors routinely go. Specifically, we examine how neighborhood socioeconomic inequality influences features of the social climate relevant for sharing routines—particularly collective trust. The ongoing debate regarding the role of social mixing in residential housing provides an important anchor point for understanding hypotheses regarding the role of SES inequality in routine activity patterns. In the optimistic view, social mixing across class brings people together in shared activities either through random mixing or through enhancing willingness to encounter others of different SES (see the discussion of the contact hypothesis). In contrast, over the last decade, a substantial literature questions social mixing as both an empirical outcome of neighborhood-SES diversity and a policy prescription for solving challenges in concentrated poverty neighborhoods (Galster 2007; Kleit and Carnegie 2011; Lees 2008; Walks and Maaranen 2008).
Extant theory suggests two mechanisms by which SES inequality might reduce the likelihood of shared routines across class. First, Robert Putnam argues—in an essay focused on race-ethnic composition—that diversity leads to a generalized decrease in trust (2007). When brought into proximity, he contends, residents of different groups experience increased distrust and social withdrawal. Putnam does not argue that diversity fosters conflict across groups but rather that it encourages an anomic tendency toward social isolation. He offers an array of evidence regarding diversity’s negative short-term effects on collective trust. Applied to shared routines, withdrawal or “hunkering down” may involve an overall reduction in the use of nonhome space (for example, in elective activities such as spending leisure time in or near the home neighborhood) or a shift of activities away from local places shared with neighbors (for example, necessity-based activities such as grocery shopping might be diverted to places neighbors are less likely to frequent). This argument suggests that urban residents are less likely to share routine activity locations with any members of their own community as the level of neighborhood inequality by SES increases.
An alternative approach links neighborhood inequality with distrust and withdrawal only between households of different socioeconomic statuses. Consistent with conflict theory in studies of race and ethnicity (Blalock 1967; Bobo 1999; Quillian 1996; Taylor 1998), lower trust brought about by increasing SES inequality increases hostile relations across, but not within, SES groups (Zubrinsky and Bobo 1996). John Hipp (2007), for instance, finds that neighborhood socioeconomic inequality is associated with higher crime. He attributes this effect to the likely influence of inequality on cohesion (network ties) across classes. Reduced cohesion, in turn, is hypothesized to limit collective capacity to achieve shared goals, such as crime reduction (Hipp and Perrin 2009). Neighborhood-level socioeconomic inequality may enhance the salience of class differences and associated tensions, reducing trust overall, but amplifying the effects of distrust on the willingness of residents to share space with other SES groups. In turn, the likelihood of actual network tie formation across class may be diminished. Drawing on this logic, our analyses explore the possibility that SES inequality decreases the likelihood of shared routine locations for groups of different SES but does not affect (or even enhance) the chances of households of the same SES sharing locations for everyday activities.
Finally, the contact hypothesis offers the more optimistic expectation that neighborhood socioeconomic diversity may extend to shared routine activity locations (Allport 1954). Initially superficial exposures to neighbors of different backgrounds foster a perception that residents have common goals and can be counted on, thereby enhancing trust. Casual observation of neighbors engaged in familiar, conventional daily routines may increase trust and the progressive incorporation of similar local shopping, worship, and leisure options into daily routines (Emerson, Kimbro, and Yancey 2002; Sampson and Bartusch 1998). Greater socioeconomic diversity at the neighborhood level provides more opportunities for the types of trust-generating cross-SES observations that may amplify willingness to adopt socioeconomically diverse activity locations as part of routines (potentially further enhancing trust). This argument is consistent with research proposing social mixing by SES as a “positive public policy tool” promoting social cohesion across class (Cameron 2003; Lees, Slater, and Wyly 2008). Accordingly, neighborhood socioeconomic diversity is expected to increase trust relevant for the willingness to share routines across SES groups. In this view, greater SES inequality would increase the tendency of neighbors of different SES backgrounds to conduct routine activities in the same locations.
We assess these competing hypotheses by examining data on activity locations of residents of sixty-five Los Angeles census tracts using the Los Angeles Family and Neighborhood Study. We fit multilevel p2 network models to dyadic tie data (shared activity locations among sampled households) to examine within-neighborhood household dyad, neighborhood, and neighborhood by household dyad (cross-level) interaction hypotheses. At the household dyad level, we explore whether higher SES reduces the likelihood of sharing routines with neighbors of any class (the material constraints and preferences hypothesis), and dissimilarity in the SES of household dyads decreases the likelihood of sharing an activity location (the social distance hypothesis). At the neighborhood level, we consider expectations that neighborhood-SES inequality decreases the overall likelihood of neighbors sharing an activity location (the generalized withdrawal hypothesis) and that this effect is mediated by collective trust. With respect to cross-level interactions, we consider whether neighborhood socioeconomic inequality moderates any observed tendency for routine activity location sorting by SES: decreasing shared activity location for households of different SES (consistent with conflict theory), or enhancing shared routines across SES (the contact hypothesis). Finally, we explore whether neighborhood-level trust amplifies the likelihood of sharing routines across SES and accounts for any observed moderating effects of neighborhood inequality on the likelihood of spatial sorting across and within SES groups.
DATA AND METHODS
We use data from the first wave of the Los Angeles Family and Neighborhood Survey. Collected between 2000 and 2002, the L.A.FANS is a stratified random sample of individuals residing in sixty-five census tracts in Los Angeles County, California (Sastry et al. 2006). Although high-poverty tracts were oversampled, the sample is representative of tracts across the income range of Los Angeles County. Within each tract, households were randomly selected and a randomly selected adult was interviewed within each household (N=2,619). We exclude households who did not indicate having at least one activity outside of their home, and those with no network ties to other households in their tract through activity locations (see dependent variable). Our sample includes remaining households with complete information on all independent variables (N=2,462).
Measures
Dependent variable. The outcome is a dichotomous indicator of whether two households living in the same neighborhood (census tract) go to the same location (block group) to conduct a routine activity. Respondents provided the address or the nearest intersection where household members commonly go for a range of routine activities—grocery shopping, school (if a child resides in the household), employment, attending religious institutions, relatives’ homes, child care, health care, a place other than home or work where the responding adult spends the most time, and places other than home where the child spends the night. These locations were geocoded and associated with the census block group where the activity occurs.1
We use neighborhood-specific activity locations (unique block groups visited by one or more households) to construct our outcome using network methods. For each neighborhood, we constructed the two-mode household-by-activity location network, what we term the ecological network (Browning and Soller 2014), where households are tied to the activity locations they visit for one or more regular activities. Then we projected this two-mode household-by-activity ecological network onto the households, which gives several one-mode household-by-household networks. These one-mode networks indicate whether pairs of households (dyads) both have a regular activity in a specific block group. The binary variables indicating whether dyads are tied through each activity location in this collection of one-mode networks are the outcome in our statistical analyses. We predict this outcome based upon characteristics of the households in the dyad (for example, having the same or different SES) and of the census tract where they live (for example, SES inequality).2
Independent variables. We construct independent variables for socioeconomic similarity of the two households in a dyad based on whether they are in the bottom, middle, or top third of the socioeconomic status distribution of L.A.FANS respondents. Socioeconomic status is a scale combining household income and educational attainment. Household income is measured in dollars.3 Educational attainment is measured in nineteen categories.4 The correlation between logged income and education is 0.34. To measure household socioeconomic status, we standardize income and education across the households, average the z-scores to get a combined index, and divide the scale into thirds. The low-SES tertile has a median income of $15,000 and seven years of education. The middle-SES group has a median income of $24,000 and twelve years of education. The high-SES group has a median income of $70,000 and a bachelor’s degree. In the multilevel models, we include a set of dummy variables indicating that households in each dyad are in the same specific category of SES (low, middle, or high SES) or different specific categories of household socioeconomic status (for example, one member of the dyad is low SES and the other is middle SES). The reference category is a pair of households that are both low SES.
We control for race-ethnic similarity within household dyads based on whether both respondents are white, black, Latino, or Asian-Other race-ethnicity (two households with different racial-ethnic identities is the reference category). We also include a series of additional variables describing the respondent similarity of marital status, residential tenure (lived in the neighborhood for at least two years), and parental status. These controls contrast households having the same focal characteristic (for example, both households lived in the neighborhood for at least two years) with dissimilar dyads. The final dyad control variables measure the difference in age and the distance in geographic space between the two households in the dyad. The latter variable controls for the fact that physical proximity of households likely increases shared locations of routine activities. Estimating social distance effects on shared routines requires, at a minimum, a control for physical proximity of households in the dyad (Hipp and Perrin 2009).
We include four measures of structural characteristics of the census tract where the households in the dyad reside (using 2000 Census data) that are commonly used in neighborhood research. Racial diversity is the sum of the squared proportions of white, Latino, black, Asian, and other race-ethnic groups in the tract subtracted from one. Higher values indicate greater race-ethnic diversity. Residential instability is measured with the standardized percentage of residents age five and older who moved since 1995. Immigrant concentration is the mean of the standardized percentage of the tract population that is foreign born and of the tract population that does not speak English well or at all (among those age five and older). Also, in each neighborhood, we count the total number of unique census block groups visited by each household (regardless of how many activities may have taken place in those block groups) and use the median of this number, termed the number of activity locations, as a tract-level variable.
To measure neighborhood socioeconomic inequality, we separately compute a Gini index of income inequality and a Gini index of educational inequality for each census tract.5 The income and education Gini coefficients are standardized separately, and then averaged to create a measure of combined socioeconomic inequality at the neighborhood level. Gini values are equal to one when one person has all the income-education in a neighborhood and zero if everyone has the same income-education, thus higher values of the SES inequality are indicative of more unequal income and education distributions in the tract. We include a measure of neighborhood trust based on respondents’ expressed levels of agreement (on a 5-point scale) with the following statement: “People in this neighborhood can be trusted.” The neighborhood-level measure is the mean value of the respondents in the neighborhood where they live.
ANALYTIC STRATEGY
In our analyses, the outcome is an indicator of a tie between pairs of individual households (dyads) based on the one-mode projected ecological network for households who reside in the same neighborhood. The complex nature of the data structure (cross-nesting of individuals and dyads within neighborhoods) requires an appropriate random effects approach to address multiple sources of dependency. To account for the nesting of dyads within neighborhoods, we fit multilevel regression models with neighborhood random effects. In addition, we include random effects at the individual (household) level to account for the fact that individuals are part of multiple dyads and, therefore, outcomes for pairs of dyads including the same individual are dependent. Random effects models of this form, where the individual-level random effects are at a lower level than the (dyad-level) outcome, are nonstandard, but have been developed in the networks literature. Specifically, the network model accounts for dependence across dyadic outcomes using cross-nested random effects (van Duijn, Snijders, and Zijlstra 2004; Zijlstra, van Duijn, and Snijders 2006). We extend the p2 model to the multilevel setting to account for the nesting of dyads within neighborhoods, as described.
The outcome of interest, Yijk, is an indicator that dyad i from neighborhood (tract) j is connected through activity location k. We model the log odds of dyad i in tract j being tied through activity location k as
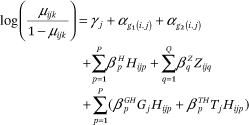
where Yj is the tract-specific random intercept, ag 1(i,j) and ag 2(i,j) are random effects associated with individual one and individual two who make up dyad i in tract j (for example,, g1(i,j) is a function that maps the ith dyad in the jth tract to the index of the first individual in the dyad; g2(i,j) is defined similarly), Hijp is an indicator of SES category p similarity in dyad i from tract j, 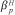 are corresponding fixed effects, the Zijqs are dyad-level control variables, and the
are corresponding fixed effects, the Zijqs are dyad-level control variables, and the 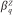 s are corresponding fixed effects. The remaining terms capture cross-level interactions between the dyad-level SES similarity variables and tract-level measures of inequality (Gj) and trust (Tj).
s are corresponding fixed effects. The remaining terms capture cross-level interactions between the dyad-level SES similarity variables and tract-level measures of inequality (Gj) and trust (Tj).
We assume that
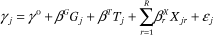
where εj ~ iid N(0,τ2), γo is the overall mean, βG and βTare fixed effects corresponding to neighborhood levels of inequality and trust respectively, the Xjrs are tract-level control variables, and the 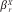 s are the associated fixed effects. In addition, we assume that αl = α0 + νl where νl ~ iid N(0,σ2). To fit this model, we use the glmer function in the lme4 package (version .999999–0) in R (version 3.0.1). To accommodate the individual effects, it was necessary to edit the design matrix for the random effects. Neighborhood-level variables are mean-centered for ease of interpretation.
s are the associated fixed effects. In addition, we assume that αl = α0 + νl where νl ~ iid N(0,σ2). To fit this model, we use the glmer function in the lme4 package (version .999999–0) in R (version 3.0.1). To accommodate the individual effects, it was necessary to edit the design matrix for the random effects. Neighborhood-level variables are mean-centered for ease of interpretation.
RESULTS
Table 1 presents the descriptive statistics for the households, neighborhoods, and household dyads in the analytic sample. The sample is majority Latino (56 percent) with a median income of $27,000 and a modal education level of high school diploma. Almost 60 percent of household dyads match on racial-ethnic identity; 39 percent are dyads in which both households are Latino. Sixty percent of dyads are two households with children. Approximately half of the neighbor pairs (dyads) have the same socioeconomic status, 15 percent low, 13 percent middle, and 21 percent high. The remaining dyads have different socioeconomic status with many more low-middle SES and middle-high SES than highly divergent low-high SES pairs of neighbors.
Household Dyad Effects
Table 2 reports results from multilevel p2 models of whether two households living in the same neighborhood go to the same activity location. Model 1 includes only dyad-level SES and control variables. The tables present coefficients as log odds; in the discussion that follows we refer to the odds ratios for interpretation. The results show that two neighbors of low socioeconomic status are the most likely to routinely go to the same places. The odds of a routine activity tie for dyads with two middle-SES or two high-SES households are 13 percent (p < 0.05) and 15 percent (p < 0.10) lower, respectively, than for two low-SES neighbors. Pairs of households with different SES also have lower likelihoods of going to the same location than low-SES dyads; the odds of going to the same activity location for dyads with low- and middle-SES households are 14 percent lower (p < 0.001) than for low-SES dyads. Comparable figures for low-high and mid-high SES combinations are 21 percent (p < 0.05) and 16 percent lower (p < 0.001), respectively, than for low-SES dyads. Consistent with the expectation that higher income offers more flexibility in activity locations, dyads involving higher-SES households (whether similar or dissimilar) are somewhat less likely to encounter other households from the same neighborhood of any SES than low-SES households are to encounter one another. Consistent with a social distance expectation, household pairs that are the most different in their SES (low—high) have the lowest likelihood of encountering one another. These results offer strong support for the hypothesis of spatial sorting in routine activities by SES, in contrast to the random mixing model.
Turning to dyad-level control variables, the odds of going to the same activity location for a dyad with two Latinos or two whites are 22 percent and 15 percent higher than for the average dyad where the households are of different race-ethnicities. Similarity on residential tenure and parental status also contribute to the likelihood of going to the same place; the odds of a location tie between two households with children are 45 percent higher than for a pair with a parent and a nonparent neighbor. The odds of going to the same location for a dyad with two nonparent households are 24 percent lower than neighbor pairs consisting of a parent and a nonparent.
An obvious potential explanation for the sorting patterns in model 1 is within-tract spatial segregation. In other words, the pattern may be due to the fact that the two households within each dyad live closer or farther from one another (Hipp and Perrin 2009). Accordingly, model 1 also includes the distance between the households in the dyad. The farther that households live from each other within their neighborhood, the less likely they are to go to the same routine activity location. However, analyses not presented indicate that inclusion of this measure does not alter the associations of other dyad characteristics with sharing activity locations.
Neighborhood Average Effects
Model 2 adds neighborhood socioeconomic inequality as well as tract indicators of immigrant concentration, residential instability, racial diversity, and the median number of activity locations per household. Two of the neighborhood characteristics are important. Greater racial diversity is associated with lower chances of going to the same place for routine activities (p < 0.10) (for additional discussion of race-ethnicity effects, see the sensitivity analyses section). The median number of activities is also negatively associated with location ties (p < 0.001), which indicates that the larger the number of distinct places households go to (on average), the lower the likelihood that household pairs share routines.6 Neighborhood socioeconomic inequality is also negatively, but not significantly, associated with sharing routine activity locations. Although the average negative effect of racial diversity on the likelihood of a shared activity is consistent with Putnam’s generalized withdrawal hypothesis, this association does not extend to socioeconomic inequality within neighborhoods. The effects of dyad characteristics, including SES similarity-difference, do not change substantially with the addition of tract-level factors.
Model 3 includes the average effect of neighborhood trust on the likelihood of a location tie and shows that trust increases the generalized tendency to share routines. A 1 standard deviation increase in neighborhood trust (0.44) is associated with a 17 percent increase in the odds of sharing a routine activity (p < 0.10). Of note, the coefficient for racial diversity is reduced by almost 30 percent (to nonsignificance) by including neighborhood trust. Although the coefficients for racial diversity (in model 2) and trust (in model 3) are marginally significant, the models offer suggestive evidence for the generalized withdrawal hypothesis with respect to racial diversity.
Neighborhood by Household Dyad Cross-Level Interactions
To assess whether the effects of SES household dyad similarity-dissimilarity differ by characteristics of neighborhoods, we test cross-level interactions between neighborhood socioeconomic inequality and household dyad SES similarity-dissimilarity. We then consider cross-level interactions between neighborhood trust and household dyad SES covariates. Table 3 presents the results of these models.
In model 1, the main effect of socioeconomic inequality, for two low-SES households, is not significant. For dyads with two middle- or high-SES households, the interactions with inequality are negative and significant (p < 0.05 and p < 0.01, respectively); as inequality increases, the likelihood of two neighbors of similar middle or higher SES going to the same location decreases. Both the average effects and the interaction terms are significant for dyads with one low- or middle-SES household and one high-SES household (at least p < 0.05). The likelihood of a location tie is lower for these dyads than for those with two low-SES households when inequality is average; as inequality increases, the odds of going to the same routine activity location decrease significantly. Only the pairs with one low- and one middle-SES household exhibit no such pattern by neighborhood socioeconomic inequality. The results show that increasing inequality reduces the likelihood of routinely going to the same place for all SES neighbor pairs except those with two low-SES or a low- and middle-SES household.
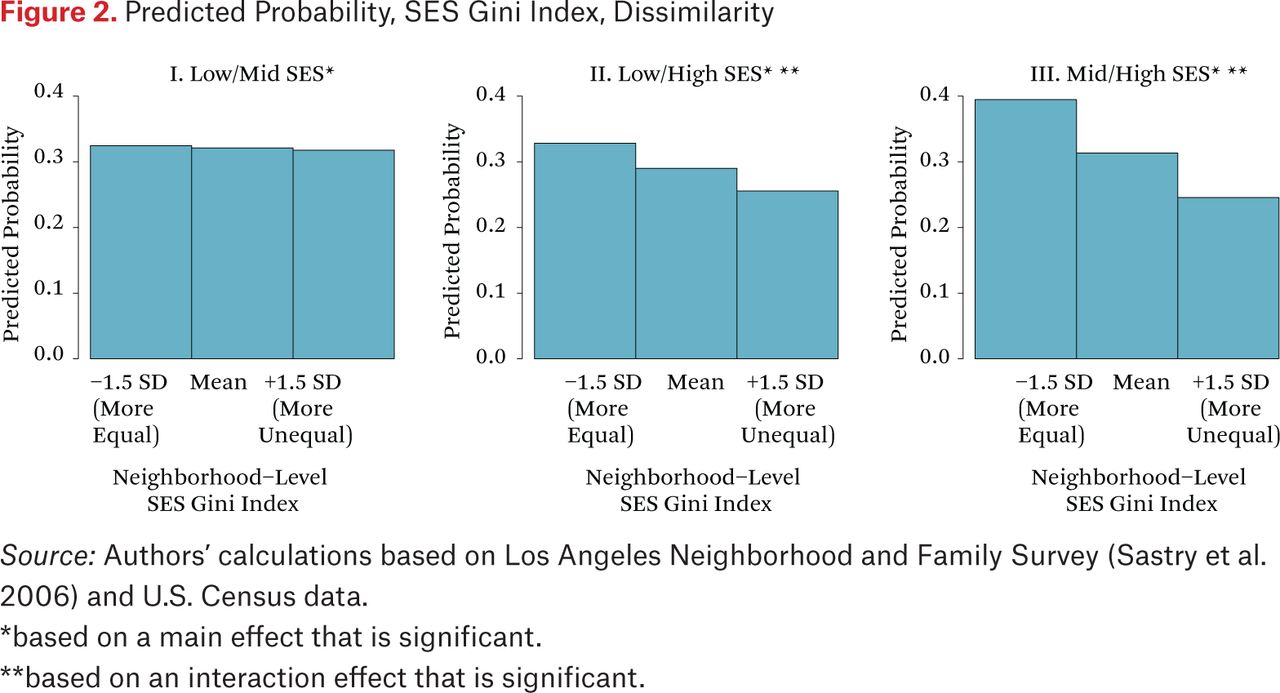
Figures 1 and 2 display these results clearly by presenting the predicted probability of two households in a randomly selected dyad visiting at least one of the same activity locations across levels of neighborhood inequality.7 Figure 1 shows the chances of contact for similar SES dyads and figure 2 presents them for dissimilar SES dyads. For dyads with two low-SES households (figure 1), the predicted probability of sharing activity spaces is about 0.35, and does not vary significantly by neighborhood socioeconomic inequality. Among dyads with two similar middle- or high-SES households (figure 1), the probability of a shared routine location is about 0.40 when living in a neighborhood with very low socioeconomic inequality (1.5 standard deviations below the mean). The probability of going to the same place is significantly lower—about .29 for middle-SES dyads and .23 for high-SES dyads—if they reside in a neighborhood with very high inequality (1.5 standard deviations above the mean). Similar patterns are observed for dyads with one high-SES household (figure 2); the probability of a shared location at low levels of inequality is 0.33 for low-high SES pairs and declines to 0.26 in high inequality neighborhoods. For middle-high SES pairs, the probability of a shared location in low inequality neighborhoods is 0.39 and declines to 0.25 in high inequality neighborhoods.

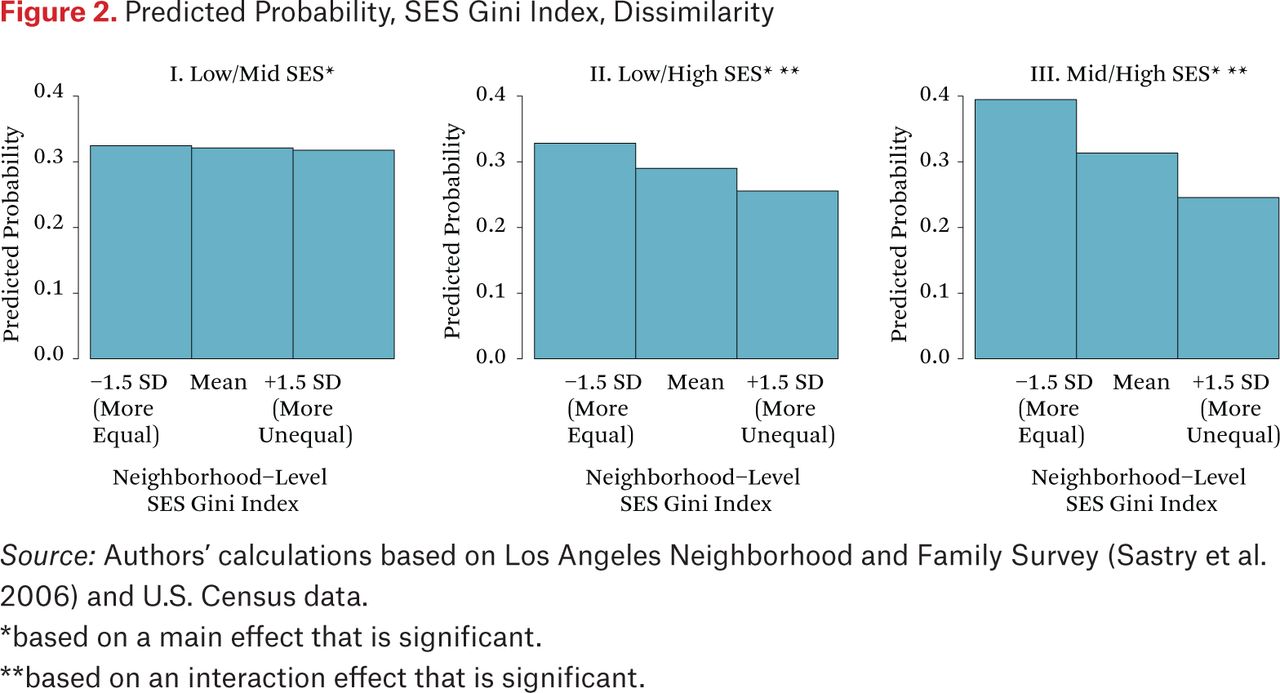
The predicted probabilities reveal an overall pattern of more limited sharing of routine activity spaces as neighborhood socioeconomic inequality increases, for dyads involving higher-SES households (whether similar or dissimilar). At high inequality, higher-SES residents have a comparatively low likelihood of encountering a low, middle, or another high-income household; this is also true for two middle-income households. This suggests a tendency toward withdrawal among higher-income groups that is amplified at higher levels of socioeconomic inequality.
Model 2 of table 3 includes cross-level interactions of neighborhood trust and dyad SES, to test whether the effect of socioeconomic inequality on sorting for dyads with higher-SES households is mediated by neighborhood trust. The findings show that the effect of trust for two households of low SES (main effect) is not significant. However, the interactions for dyads with two middle-SES households and for dyads of any dissimilar combination of SES are positive and significant. Therefore, as trust increases, the likelihood of middle-SES and SES-dissimilar dyads sharing routine locations increases. The average effects of the SES dyad combinations (when inequality and trust are at their means) by comparison to low-SES dyads are no longer significant with the exception of low-high SES dyads. The social distance sorting effect for low-high SES dyads, in neighborhoods with average levels of trust, is nontrivial; these dyads are about 18 percent less likely to share routines than low-SES dyads. This lesser tendency to go to the same locations is significantly reduced at higher levels of neighborhood trust.
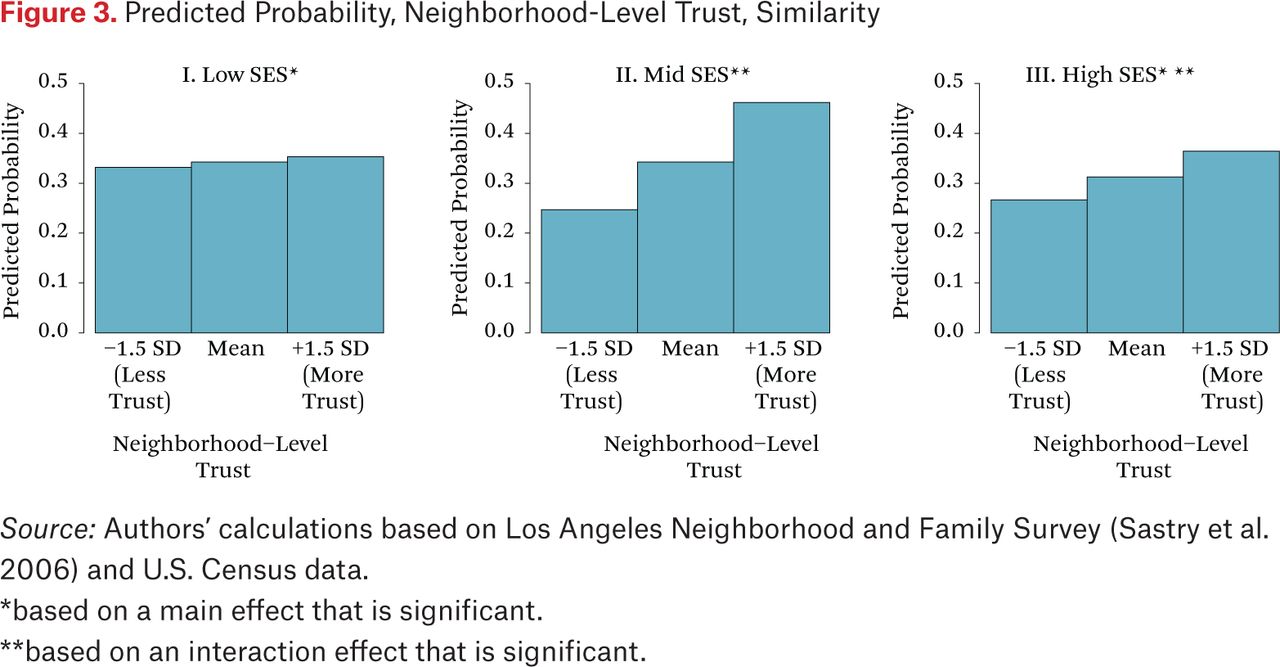
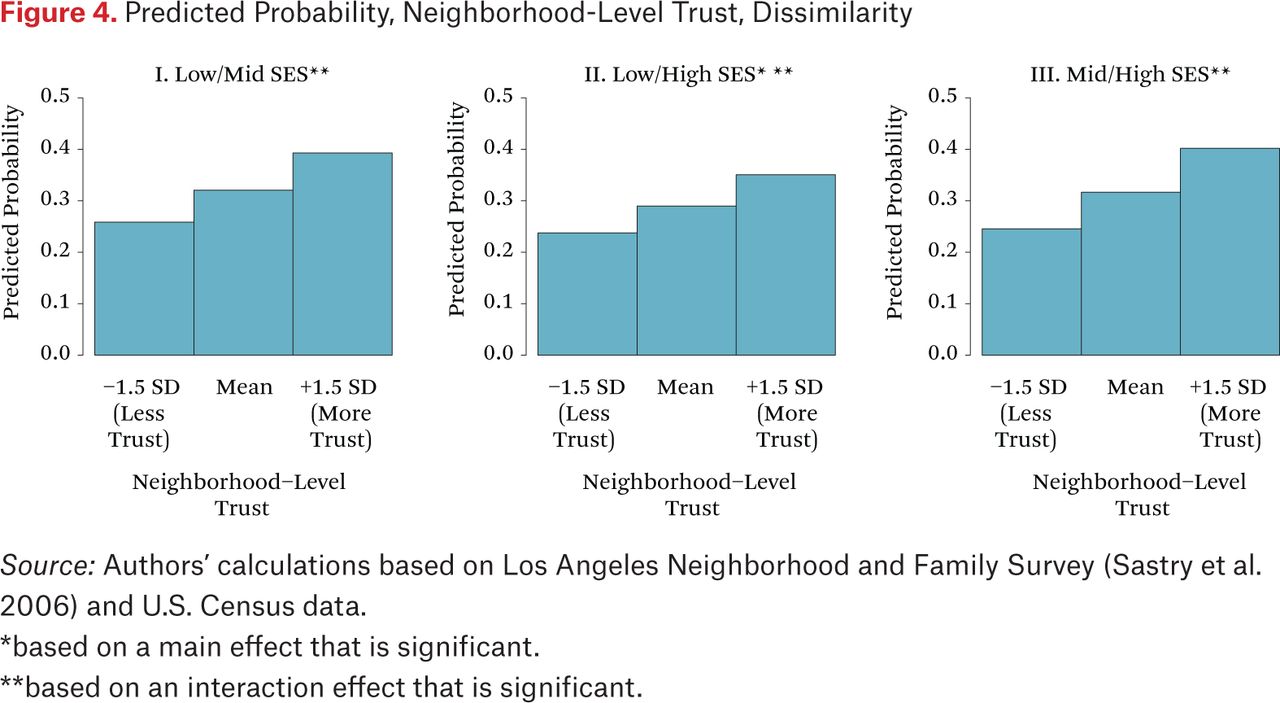
Figures 3 and 4 present the probability of the two households in a randomly selected dyad visiting at least one of the same activity locations for similar (figure 3) and dissimilar (figure 4) SES dyads across levels of neighborhood trust. The positive relationship between neighborhood trust and location sharing is particularly evident for dyads with two middle-SES households (figure 3), though it is seen for all pairs except those with two low-SES households. In neighborhoods with low perceived trust of neighbors, the probability of sharing a location is about 0.25 for all dyads other than the low-SES pairs. In high-trust neighborhoods, these probabilities of activity location contact are notably higher, between 0.35 and 0.40 for most combinations and a high of 0.46 for two middle-SES dyads. As a result, there are no statistically significant differences in the probability of shared routines by SES dyad characteristics in neighborhoods with high levels of trust, with the exception of middle-SES similar dyads, which have significantly higher chances of contact in activity locations. These results indicate that increases in neighborhood trust reduce the tendency toward sorting by SES. Moreover, introduction of trust in cross-level interactions with household dyad combinations accounts for a nontrivial portion of the inequality effects on SES sorting. Trust diminishes the magnitude of all of the inequality interactions, and to nonsignificance in three out of four cases.
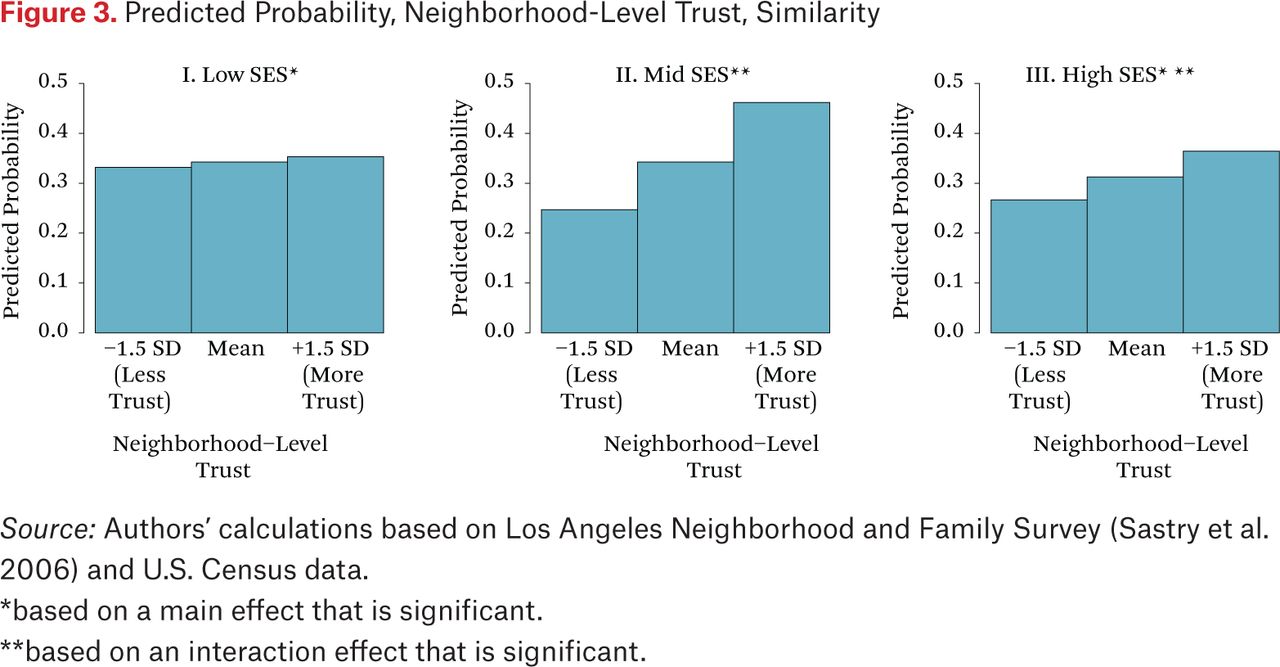
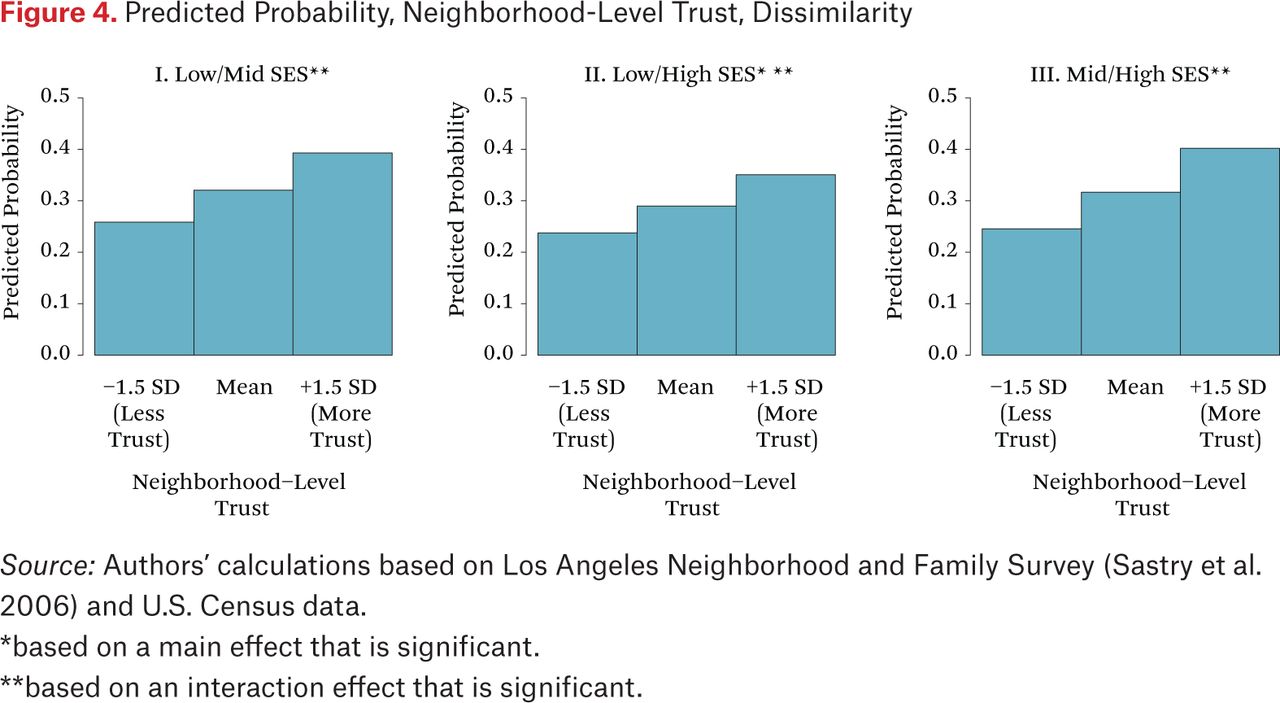
In summary, the models offer evidence that SES inequality reduces the likelihood of shared routines but only for middle- and high-income similar dyads and dissimilar dyads involving a high-income household. The pattern exhibited is consistent with the notion of a SES group-specific withdrawal effect: inequality leads higher-income residents to withdraw from shared neighborhood spaces overall, including from each other. This effect is explained, in part, by diminished neighborhood trust for these dyad combinations, with the exception of high-SES similar dyads.
Sensitivity Analyses
To determine whether the effect of neighborhood inequality is due to neighborhood economic status, we also fit models with a variety of alternative SES measures added. These include a combined index of neighborhood economic status, the poverty rate, and the percentage of households with high income, each entered separately along with socioeconomic inequality. None of the interactions between these measures and the different SES dyads are significant showing that the effect of SES inequality is not due to its correlation with absolute SES.
We also consider the possibility that the average effects of dyad SES similarity-dissimilarity and the differential effects of neighborhood SES across various household-SES dyads are confounded by race-ethnic similarity-dissimilarity (and neighborhood racial diversity). Thus, we examine interactions between race-ethnic (Latino, white, black, Asian or other) dyad similarity and neighborhood racial diversity. These analyses show only nominal changes to the magnitude and significance of the SES dyad and neighborhood-SES inequality effects.8
We examine a number of other potential neighborhood social processes that might account for the relationship of neighborhood-SES inequality with the sharing of activity locations. These include social interaction and reciprocated exchange (frequency of favor exchange, advice giving across neighbors) and organizational density (examining whether the absence of institutions and services within people’s neighborhoods might explain the tendency of higher-SES residents to go elsewhere). Neither social interaction and reciprocated exchange nor organizational density is significantly related to the tendency to share routines or to sorting by SES in this outcome. We also examine a combined measure of social cohesion (capturing the sense that neighbors are close-knit, helpful, get along, and share the same values, in addition to being trustworthy). Interactions of social cohesion with some of the SES dyad are significant, but these effects are weaker than those observed for neighborhood trust. This indicates that the sense of trust, specifically, is a uniquely important predictor of shared routines.
Finally, we conduct analyses to shed light on possible activity-location-related mechanisms that might explain the inequality and trust effects on shared routines. Models of the number of unique activities (whether they are in the same block group) and unique block groups visited (regardless of the number of activities) yield the same general conclusions. Consistent with expectations derived from the material constraints and preferences model, increasing SES is associated with more unique activities or block groups. However, cross-level interactions indicate that greater neighborhood-SES inequality increases the number of unique activities or block groups for lower-SES individuals, but is not associated with this outcome for higher status economic groups. Models of the average distance to activity locations reveal a comparable pattern of increasing distance with SES, but no evidence that inequality influences SES effects on distance traveled. These findings suggest that, with greater neighborhood inequality, lower-SES residents may be increasing the number of locations they visit in a manner that does not generate substantial differences in the average distance traveled but nevertheless produces fewer shared locations with higher-SES households. This somewhat counterintuitive result may be due to lower-SES groups adopting new nonhome activities (for example, child care or leisure activities away from home or its immediate vicinity) in response to amplified distrust of the local environment. Higher-SES groups do not appear to change the number of activities or the distance traveled with greater inequality, but may be choosing a more idiosyncratic set of destinations, perhaps due to the role of diminished trust on the willingness to share locations with neighbors of any class. These findings point to the need for more fine-grained analysis to determine the nature of routine activity patterns by SES associated with greater inequality.
CONCLUSION
The voluminous literature on segregation has focused primarily on residential segregation within units of analysis such as census tracts, cities, and metropolitan regions. We extend this work to investigate patterns of integration and segregation by socioeconomic status in the activity locations neighborhood residents frequent in the course of their daily routines. We first consider the extent to which, conditional on residence in the same census tract, neighbors of the same or different SES frequent the same routine activity locations. We hypothesize that variation in material constraints and preferences by SES result in a lower likelihood of sharing routines for SES dyads involving higher-income households. Higher-SES residents have more extensive options for where they go (given greater affordability and accessibility). In turn, they may be less likely to share routine activity locations with neighbors of any SES. We also expect that social distance between residents of different economic statuses would lower the likelihood of sharing activity locations. Both hypotheses were supported in multilevel p2 models. Unsurprisingly, neighbor dyads with one low- and one high-SES household are the least likely of all SES pairs to go to the same activity locations. The likelihood of sharing routine activity locations are also by far the greatest for two low-income neighbors.
These findings offer robust evidence of spatial sorting in routine activity locations by SES among residents of the same neighborhood, even after accounting for within-neighborhood residential segregation (as captured by variation in distance between home addresses). Approaches to segregation that go no further than residential location neglect systematic patterns of spatial sorting that limit the likelihood of cross-SES exposure. The results are consistent with the claims of social-mixing critics, who argue that spatial propinquity based on residence is not a sufficient condition to ensure exposures across economic lines in the course of daily routines (Lees 2008). They also complement Hipp and Perrin’s (2009) finding that social distance in neighborhood ties exist, even after controlling for how close the residents live to one another.
Second, we investigate whether neighborhood conditions independently influence the likelihood of shared routines. We focus particularly on the role of neighborhood-SES inequality in generating overall differences in the likelihood of shared routines. Although the direction of the average SES-inequality effect is consistent with Putnam’s (2007) hypothesis that diversity results in a generalized tendency toward withdrawal, only racial diversity achieves significance in the model. Further, considering the role of neighborhood trust in these relationships, we find reduced trust is an important reason why racial diversity diminishes the sharing of activity locations. Although beyond the scope of the current analysis, these results call for more attention to the role of race-ethnicity as a source of spatial sorting in daily routines.
Third, we examine whether the lesser tendency of dyads that include high-status households to share routine locations than other SES dyads varies depending on the extent of SES inequality in the neighborhood. Here we found consistent evidence that increases in neighborhood-SES inequality are associated with more pronounced spatial sorting in routine activity locations for higher-SES dyads. Under conditions of lower-SES inequality (versus higher-SES inequality), sorting in where neighbor households go is much more limited for middle- and higher-SES households. Thus, the assumption that residential integration is at least partly replicated in activity spaces appears to hold for residents of neighborhoods with low levels of inequality. In contrast, as SES inequality increases, middle- and higher-income residents are progressively less likely to encounter any neighborhood residents when they are away from home.
These findings have potentially important implications for understanding the conditions under which social mixing across SES—as manifest in spatial intersection—occur. More pronounced differences in the SES levels of neighborhood residents appear to interfere with the potential for cross-class mixing. Consistent with this finding, evidence suggests that cross-SES interactions are more likely when income heterogeneity is only moderate (Brophy and Smith 1997; Rosenbaum, Stroh, and Flynn 1998). Research on the impact of neighborhood income mix also shows that lower-income residents experience greater income growth if they live in neighborhoods that have larger percentages of middle-income but not high-income neighbors (Casciano and Massey 2008; Galster et al. 2008), reinforcing the importance of lower inequality for interclass relations. Of interest was the lack of evidence supporting an out-group avoidance explanation for the patterns of observed sorting by SES. We found no evidence that increases in SES inequality led to the diminished tendency to share activities with those of other classes versus those of the same class. The reduced likelihood appears to affect most dyad combinations involving higher-income households—whether similar or dissimilar.
These findings also provide some support for Putnam’s expectation of an overall pattern of withdrawal as diversity in SES increases but with a class-specific manifestation of this tendency. Lower-SES residents were not significantly less likely to share routines with one another as inequality increased. Lower-SES residents are likely to have more limited flexibility in activity location choice—perhaps choosing (or adding) routine activities that limit contact with other SES groups, but not their own.
Also partially consistent with Putnam’s expectations, we find relatively consistent evidence of neighborhood trust effects on the impact of dyad SES on sharing routing locations. As neighborhood trust increased, routine activity sharing among higher- and dissimilar-SES neighbors also generally increased. Indeed, at high levels of trust we found no significant evidence of spatial sorting by SES. Moreover, a nontrivial proportion of the SES inequality effect on the dyad-level SES sorting tendency was explained by trust. Trust appears to play an important role in the willingness of residents of different SES backgrounds to share daily routines. The findings also point to trust as a key pathway through which neighborhood socioeconomic inequality results in more limited sharing of routines. In combination, these results address the conditions under which, for instance, mixed-income housing and gentrifying neighborhoods will yield shared public space. To the extent that such public space sharing reinforces and enhances neighborhood social climates (Browning et al., forthcoming), these findings may shed light on extant research linking inequality with other negative outcomes such as crime (Hipp 2007) and poor health (Wilkinson and Pickett 2009).
Seen in the context of the increasing hollowing out of the middle class in the U.S. context (Bischoff and Reardon 2014; Galster, Cutsinger, and Booza 2006), these findings suggest that housing strategies seeking to place low-income residents in stable neighborhoods characterized by lower-middle residents and middle-income (as opposed to affluent) residents may be increasingly difficult to realize. To the extent that increasing SES inequality more generally is associated with reduced prevalence of middle-income communities, targeting such neighborhoods for placement of low-income housing may prove challenging. In addition, currently middle-income neighborhoods may be on a downward trajectory, diminishing the long-term benefits of mixed-income housing developments in these locations.
We emphasize the importance of seeking to develop strategies that buffer high-SES inequality neighborhoods (including gentrifying neighborhoods) from the pervasive mistrust that results in withdrawal from shared space. Socioeconomically disadvantaged residents of mixed-income housing developments should have the opportunity to benefit from exposure to neighborhoods composed of residents of all classes, not just middle-income residents with whom the development of trust is less complicated. Homogeneously high-SES urban areas also reduce exposure of affluent residents to the socioeconomic spectrum of urban areas, exacerbating class insularity. Further research on the conditions under which residentially proximate low- and high-income residents do not suffer trust deficits will promote the development of mixed-income housing strategies that counter increasingly prominent class-based spatial divisions.
Our analyses are characterized by a number of limitations. First, our data are limited to the Los Angeles context. Thus, it is unclear whether these patterns extend to cities with different social, demographic, and economic structures. Second, information on the routine activity locations of L.A.FANS respondents is limited to a subset of common destinations. Currently, the L.A.FANS is the only available neighborhood-focused social survey data to also collect activity space information of any kind, though emerging projects are attempting to address limitations in the availability of rich information on routine activity locations (Browning and Soller 2014). Third, our sample of neighborhoods is somewhat small for investigating variability in neighborhood-level SES inequality. Nevertheless, the results of these analyses warrant future efforts to explore the effects of distinct types of SES distribution on household-level SES sorting tendencies. Finally, our data are cross-sectional, limiting our ability to infer causal effects. For instance, although trust is likely to foster shared routines, the reciprocal relationship is also likely—shared routines may lead to enhanced trust. Longitudinal data will provide an opportunity to more rigorously explore the mediating effects of trust in the link between inequality and shared routines.
The analyses reported here are among only a few studies to investigate activity space segregation and, to our knowledge, the only existing study to consider multilevel influences on routine activity sorting by SES. Although infrequently considered in the extant literature, patterns of shared exposure through activity routines is likely to be an increasingly common focus of investigation as richer data on urban activity spaces become more readily available. These data hold substantial promise to yield important insights into the nature of everyday patterns of social integration and isolation.
Acknowledgments
The authors wish to thank Jonathan Dirlam, Ruth Peterson, Mei-Po Kwan, Yanan Jia, and Samuel Bussmann. This research was supported by the National Institute on Drug Abuse R01 DA032371 03 (“Adolescent Health and Development in Context”), the National Science Foundation DMS-1209161 (“Bayesian Methods for Socio-Spatial Point Patterns and Networks”), and the Ohio State University Institute for Population Research (NICHD P2CHD058484).
FOOTNOTES
↵1. We include only activity locations in block groups in California. On average, households reported 5.04 nonhome activities with valid block group locations.
↵2. Combining each household dyad with each possible tie through a block group location within a tract results in a total of 3,824,943 dyad-location records for analysis.
↵3. The income data include RAND-imputed values to deal with nonresponse using education, marital status, family composition, immigrant status, health status, and neighborhood poverty as predictors (Bitler and Peterson 2004).
↵4. Educational attainment is measured by nineteen categories including last year of school completed for those with less than a high school education and highest degree obtained.
↵5. Income is measured by eleven categories ranging from less than $10,000 to $200,000 or more. The income Gini is constructed using the median income for each category, and the estimated median for the open-ended category at the top of the distribution (Parker and Fenwick 1983). For the tracts with no households in the top two categories, we use the average median value for all tracts in L.A. County. The mean of the unstandardized income Gini is 0.40 (s=0.05). To calculate the Gini coefficient for education, we follow Vinod Thomas, Yan Wang, and Xibo Fan (2001), midpoints used in parentheses: zero years, one to four years (2.5), five to six years (5.5), seven to eight years (7.5), nine years, ten years, eleven years, twelve years and no high school diploma, twelve years and diploma or equivalent, less than one year of college (12.5 years), one or more years of college but no degree (13.5), associate’s degree (14), bachelor’s degree (16), master’s degree (18), professional degree (19), and doctoral degree (20 years). The mean of the unstandardized education Gini coefficient is 0.23 (s=0.09).
↵6. Inclusion of the average household number of unique locations as a control is a somewhat conservative approach to assessing inequality effects because the increased number of locations traveled to is a possible mechanism linking inequality with the extent of shared locations. Although the magnitude of the main inequality effect is reduced somewhat with the inclusion of median number of activities, the effect is not significant with or without median number of activities included in the model. Moreover, the cross-level interactions between inequality and the dyad-SES similarity covariates are only nominally affected by inclusion of median number of activities.
↵7. The model estimates the probability of dyad i in neighborhood j having visited the same specific activity location k,
 , which we use to compute the probability of each dyad having visited at least one of the same activity locations. We use the empirical median of the number of unique activity locations across the tracts, NA, in estimating this probability. We calculate predicted probabilities for each dyad-level covariate pattern (for example, similarity on race, marital status, and so on) and average these probabilities using weights that correspond to the frequency of each covariate pattern in the sample. Because our model includes no activity-specific terms,
does not depend on k.
, which we use to compute the probability of each dyad having visited at least one of the same activity locations. We use the empirical median of the number of unique activity locations across the tracts, NA, in estimating this probability. We calculate predicted probabilities for each dyad-level covariate pattern (for example, similarity on race, marital status, and so on) and average these probabilities using weights that correspond to the frequency of each covariate pattern in the sample. Because our model includes no activity-specific terms,
does not depend on k.
↵8. The impact of race-ethnicity on spatial sorting in routine activities within neighborhood and the effects of neighborhood diversity are significant substantive issues of their own. However, a full treatment of the role of race-ethnicity alone or in combination with socioeconomic influences is beyond the scope of this paper.
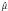

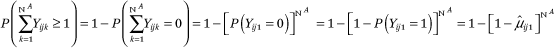
- © 2017 Russell Sage Foundation. Browning, Christopher R., Catherine A. Calder, Lauren J. Krivo, Anna L. Smith, and Bethany Boettner. 2017. “Socioeconomic Segregation of Activity Spaces in Urban Neighborhoods: Does Shared Residence Mean Shared Routines?” RSF: The Russell Sage Foundation Journal of the Social Sciences 3(2): 210–31. DOI: 10.7758/RSF.2017.3.2.09. The authors wish to thank Jonathan Dirlam, Ruth Peterson, Mei-Po Kwan, Yanan Jia, and Samuel Bussmann. This research was supported by the National Institute on Drug Abuse R01 DA032371 03 (“Adolescent Health and Development in Context”), the National Science Foundation DMS-1209161 (“Bayesian Methods for Socio-Spatial Point Patterns and Networks”), and the Ohio State University Institute for Population Research (NICHD P2CHD058484). Direct correspondence to: Christopher R. Browning at browning.90{at}osu.edu, Department of Sociology, The Ohio State University, 238 Townshend Hall, 1885 Neil Ave Mall, Columbus, OH 43210; Catherine A. Calder at calder{at}stat.osu.edu, Department of Statistics, The Ohio State University, 429 Cockins Hall, 1958 Neil Ave., Columbus, OH 43221; Lauren J. Krivo at lkrivo{at}sociology.rutgers.edu, Department of Sociology, Rutgers, The State University of New Jersey, 26 Nichol Avenue, New Brunswick, NJ 08901; Anna L. Smith at smith.11066{at}buckeyemail.osu.edu, Department of Statistics, The Ohio State University, 404 Cockins Hall, 1958 Neil Ave., Columbus, OH 43221; and Bethany Boettner at boettner.6{at}osu.edu, Institute for Population Research, The Ohio State University, 65 Townshend Hall, 1885 Neil Ave Mall, Columbus, OH 43210.
Open Access Policy: RSF: The Russell Sage Foundation Journal of the Social Sciences is an open access journal. This article is published under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.
REFERENCES
In this issue




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Jump to section
Related Articles
Cited By...
- No citing articles found.